

 JetBrains publie la version 2019.2 de DataGrip
JetBrains publie la version 2019.2 de DataGripson EDI destiné aux administrateurs de bases de données et développeurs travaillant avec des SGBD SQL
Début avril, JetBrains a annoncé la sortie de la version 2019.1 de DataGrip, son EDI destiné aux administrateurs de base de données et aux développeurs travaillant avec des bases de données SQL. C'était la première mise à jour majeure de cette année, et pour une mise à jour de ce rang, les nouveautés étaient bien au rendez-vous. Il s'agissait entre autres du support de nouvelles bases de données et de plusieurs améliorations apportées à la boite de dialogue de connexion. La navigation et la recherche ont également été facilitées et rendues plus productives dans l'EDI.
La deuxième grosse mise à jour annuelle de l'EDI vient de sortir et embarque aussi son lot de nouveautés et améliorations. JetBrains met par exemple en avant une nouvelle fenêtre d'outil appelée Services, la recherche en texte intégral, le filtrage de sources de données pendant la navigation, le nommage des onglets de résultats, entre autres ; des nouveautés que nous présenterons ici avec plus de détails.
Fenêtre doutil Services
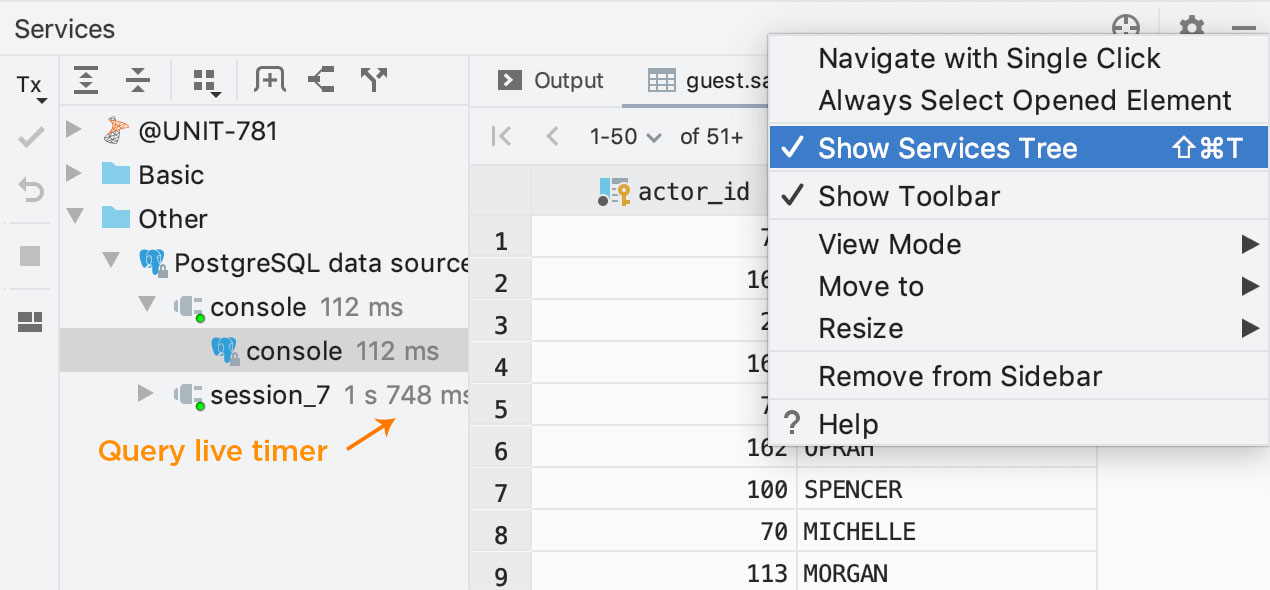
Tous les EDI de JetBrains ont maintenant une nouvelle fenêtre doutil appelée Services. Dans DataGrip, elle sera un endroit unique où vous pourrez observer et gérer toutes les connexions. Si vous utilisez le plugin Docker, les services correspondants apparaîtront également dans cette nouvelle fenêtre doutil. Cette dernière vous fournit également une autre fonctionnalité demandée : un query live timer. Grâce à cette fonctionnalité, pour toute connexion qui exécute une requête, il est possible de voir combien de temps cela a pris en regardant juste sur le côté droit de la fenêtre d'outil Services.
Recherche en texte intégral
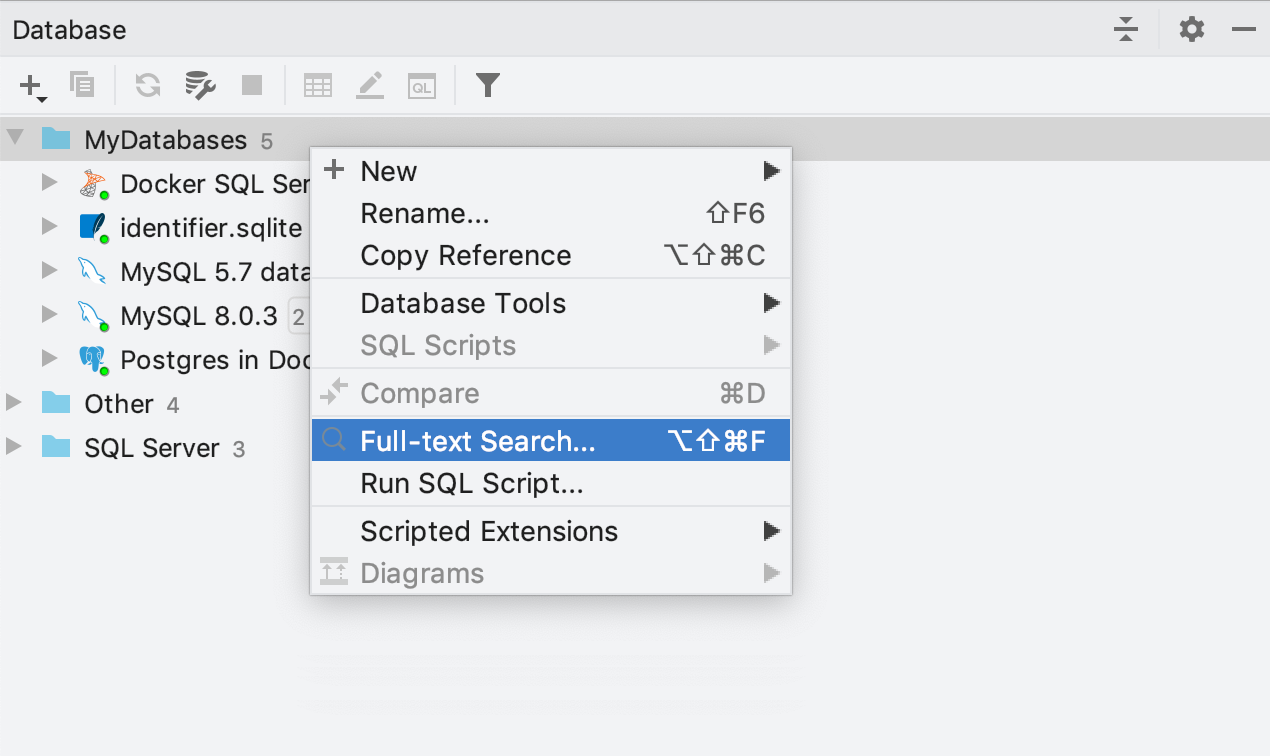
Vous pouvez désormais rechercher des données nécessaires même si vous ne connaissez pas leur emplacement exact. Faites un clic droit sur la source de données ou sur un groupe de sources de données dans lequel vous souhaitez effectuer la recherche, puis sélectionnez "Full-text Search". Vous verrez une boîte de dialogue dans laquelle entrer la chaîne. Vous verrez la liste des sources de données dans lesquelles effectuer la recherche et vous pourrez définir certaines options pour votre recherche. En outre, vous pouvez voir les instructions SQL particulières que DataGrip exécutera pour effectuer la recherche de données.
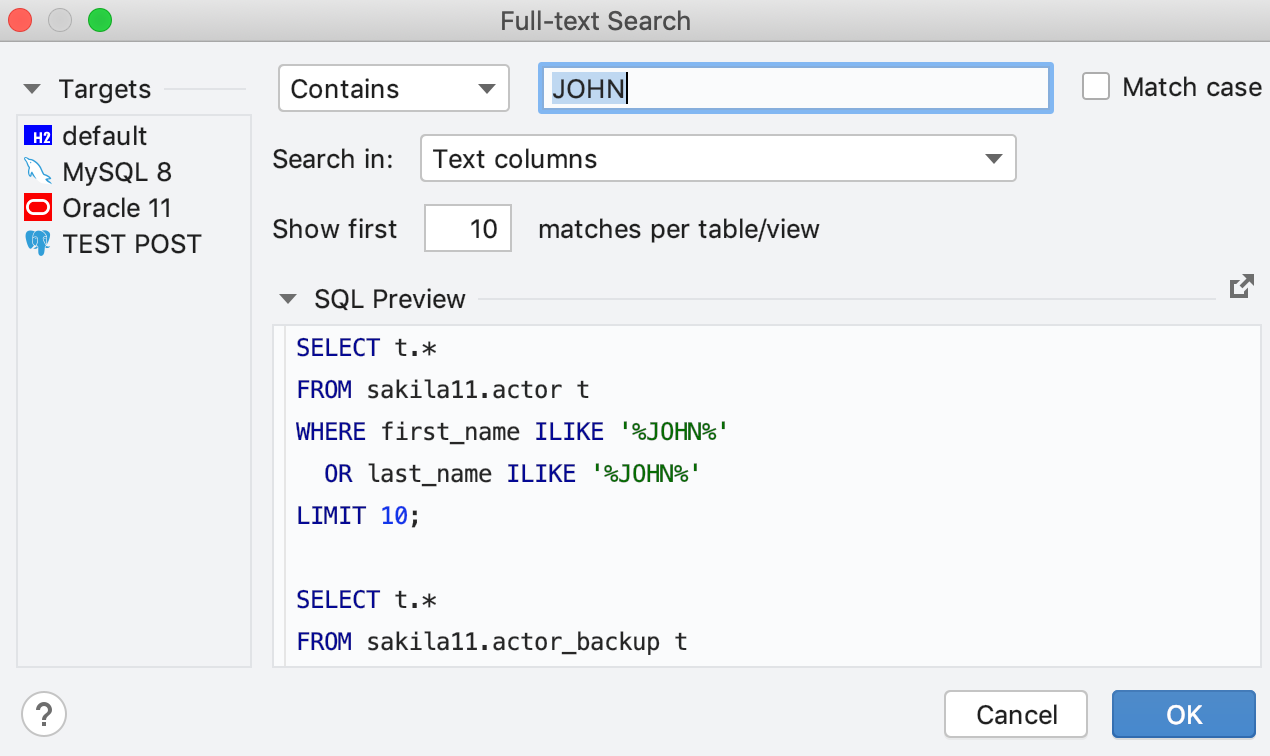
Dans les bases de données PostgreSQL, MySQL et MariaDB, vous pouvez choisir de rechercher uniquement dans les colonnes indexées. Pour utiliser ce mode, sélectionnez "Seules les colonnes avec des index de recherche en texte intégral" dans le menu déroulant "Rechercher dans". Dans Oracle, les index suivants sont utilisés, sils existent : context, ctxrule, ctxcat. Et dans SQL Server, la recherche prend en compte les index de recherche en texte intégral.
Si le mode "Toutes les colonnes" est sélectionné, la recherche couvrira les colonnes ne prenant pas en charge l'opérateur LIKE, par exemple les colonnes de type JSON. Les valeurs de ces colonnes sont préalablement converties en chaîne. Dans Cassandra, DataGrip crée plusieurs requêtes pour une table, car la condition OR nest pas prise en charge par la base de données.
Éditeur de données
Dans l'éditeur de données, la taille de la page (le nombre de lignes à afficher) est facile à modifier. Maintenant, pour définir le nombre de lignes que vous voulez extraire de la base de données, vous pouvez le faire à partir de la barre doutils du jeu de résultats.
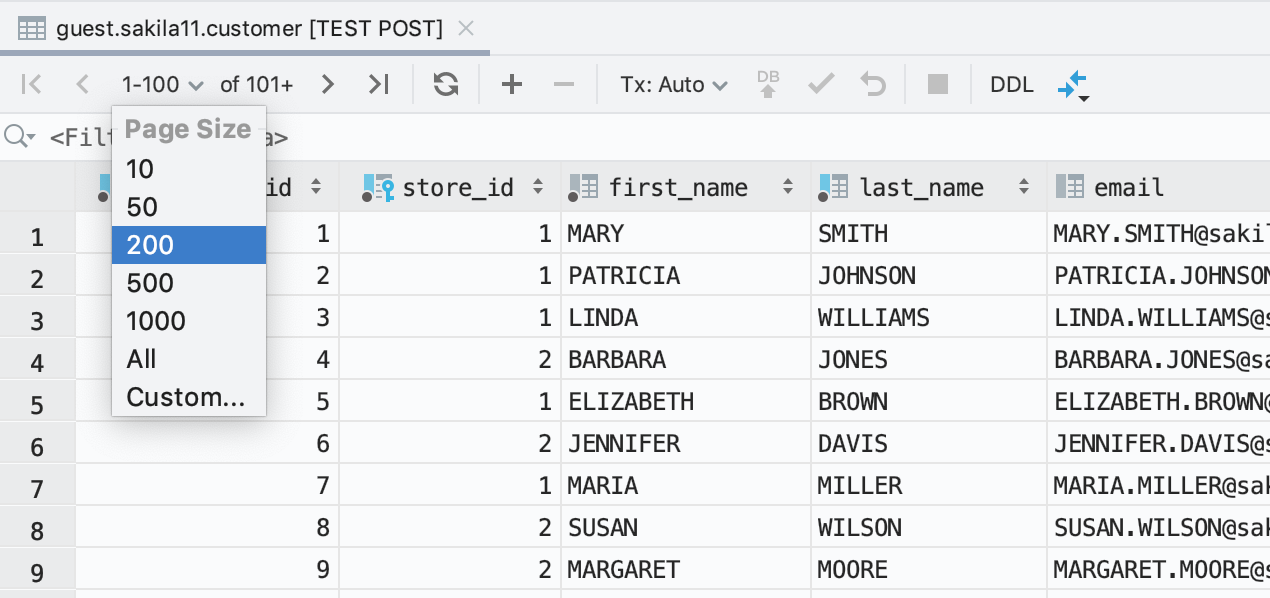
Une autre amélioration pour les résultats est la possibilité de nommer les onglets : vous pouvez simplement utiliser le commentaire avant la requête pour nommer l'onglet de résultats.
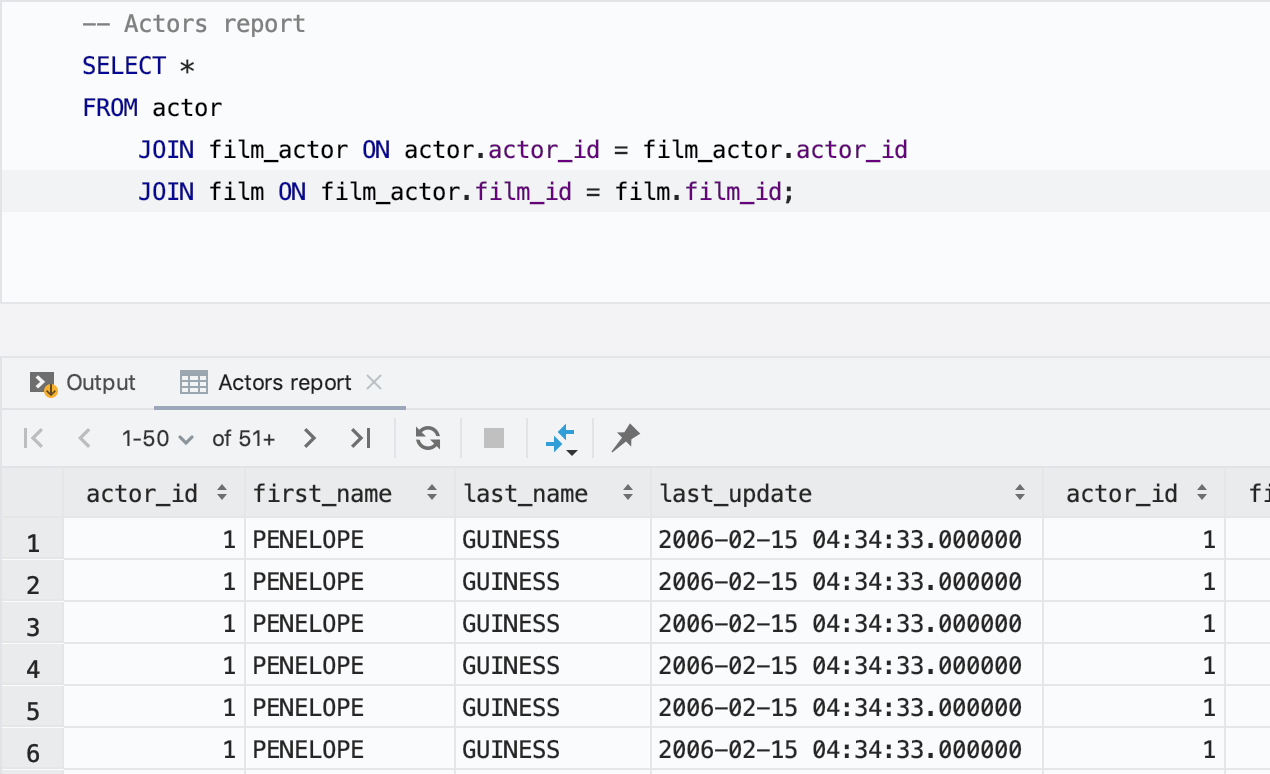
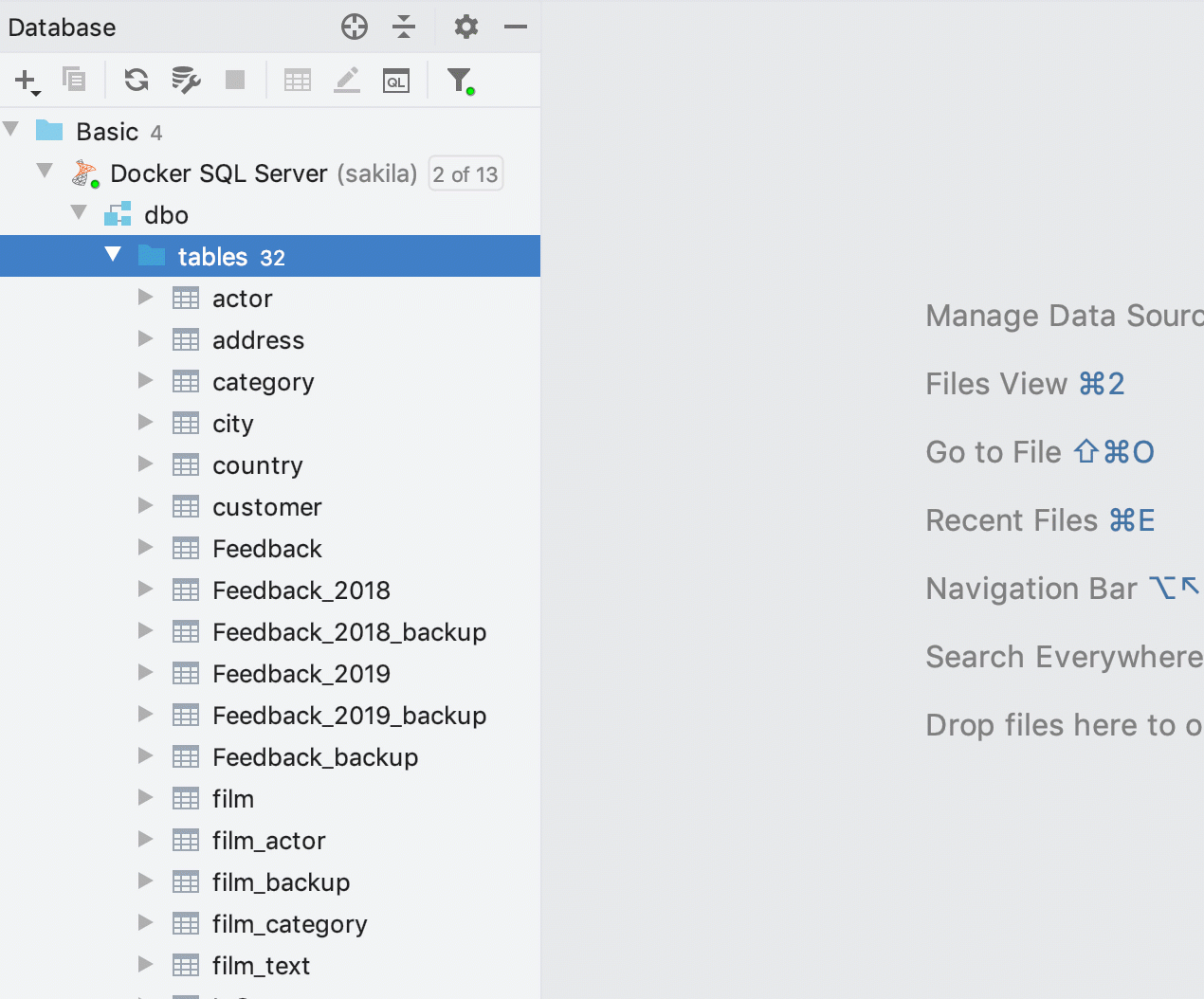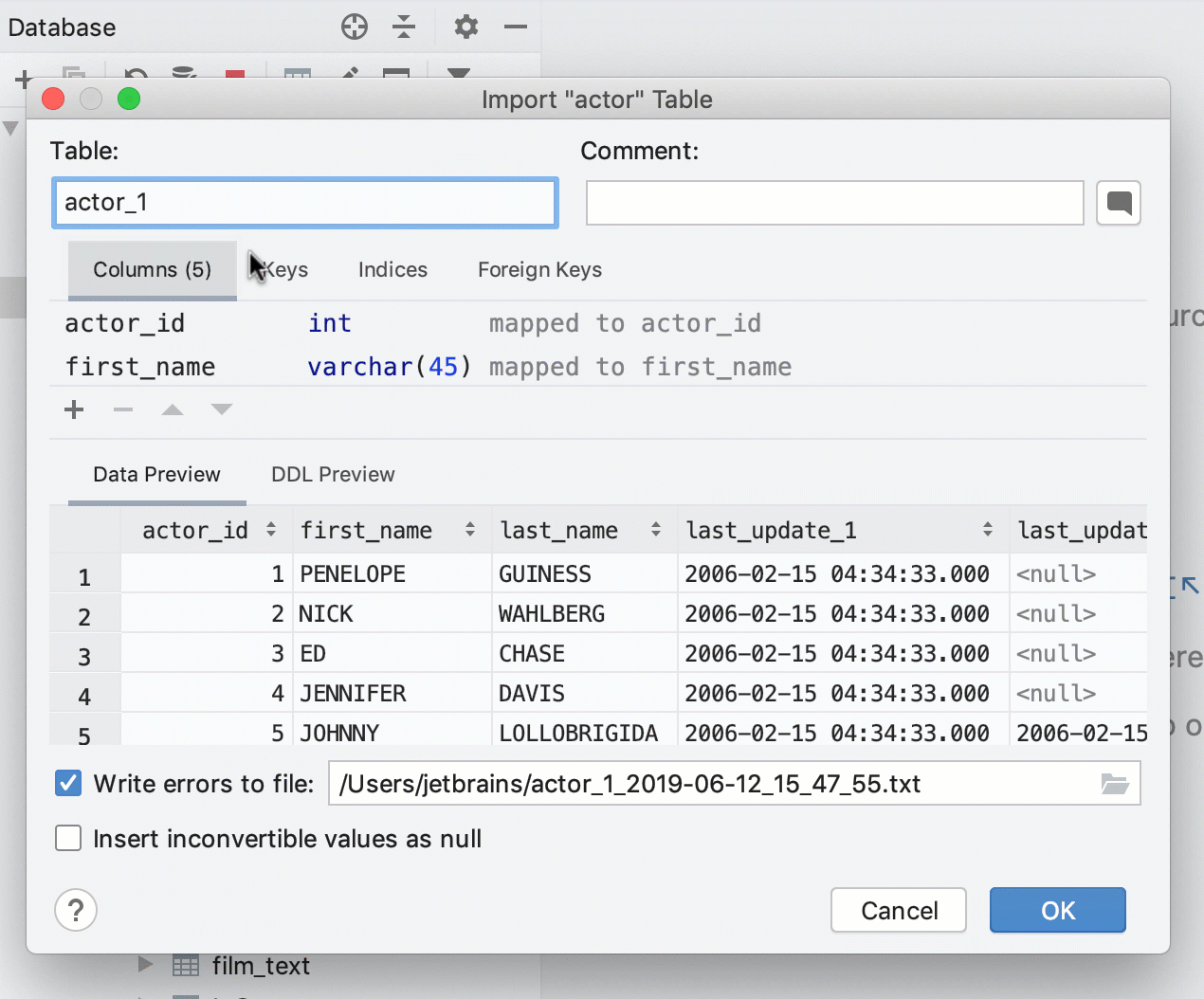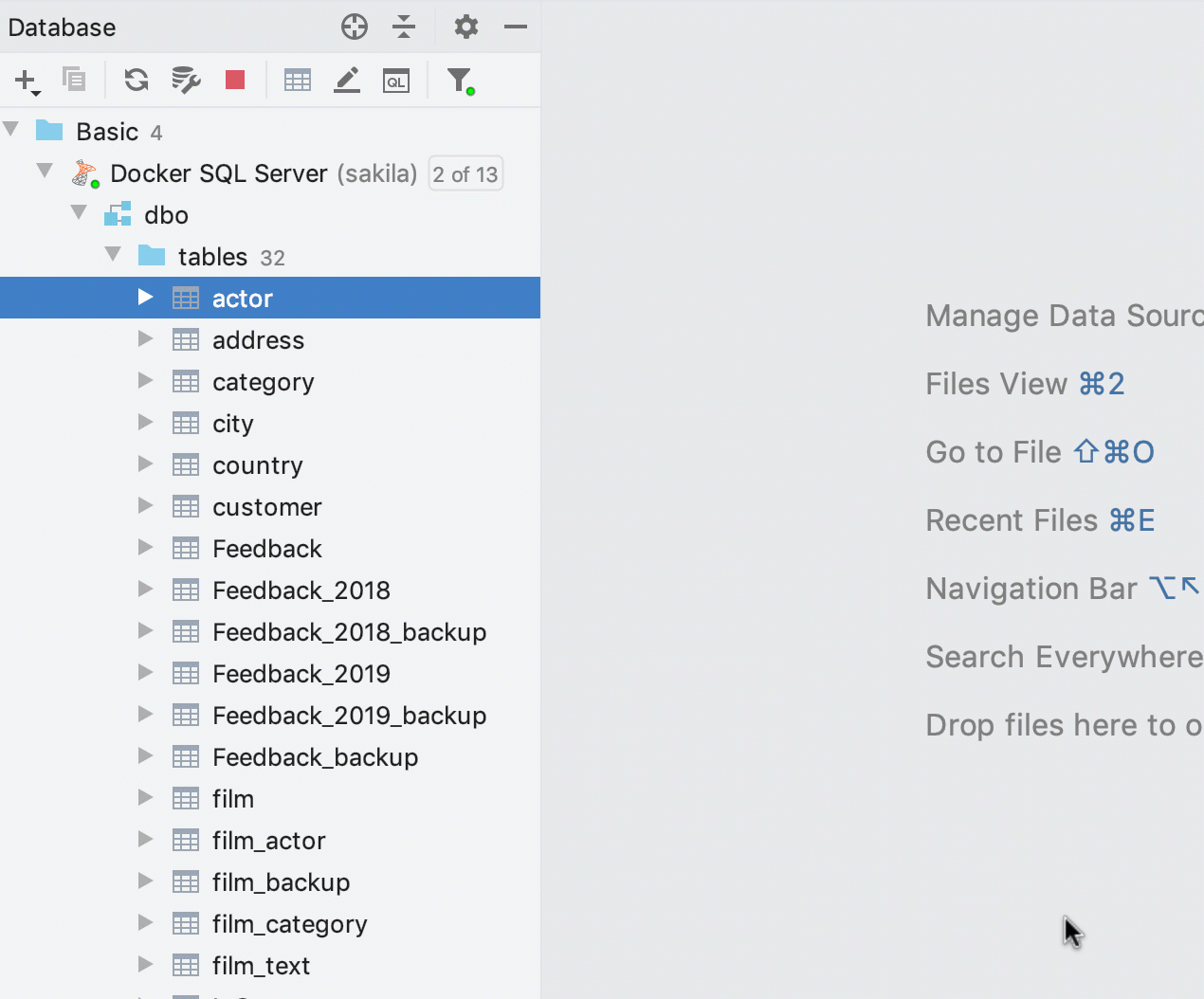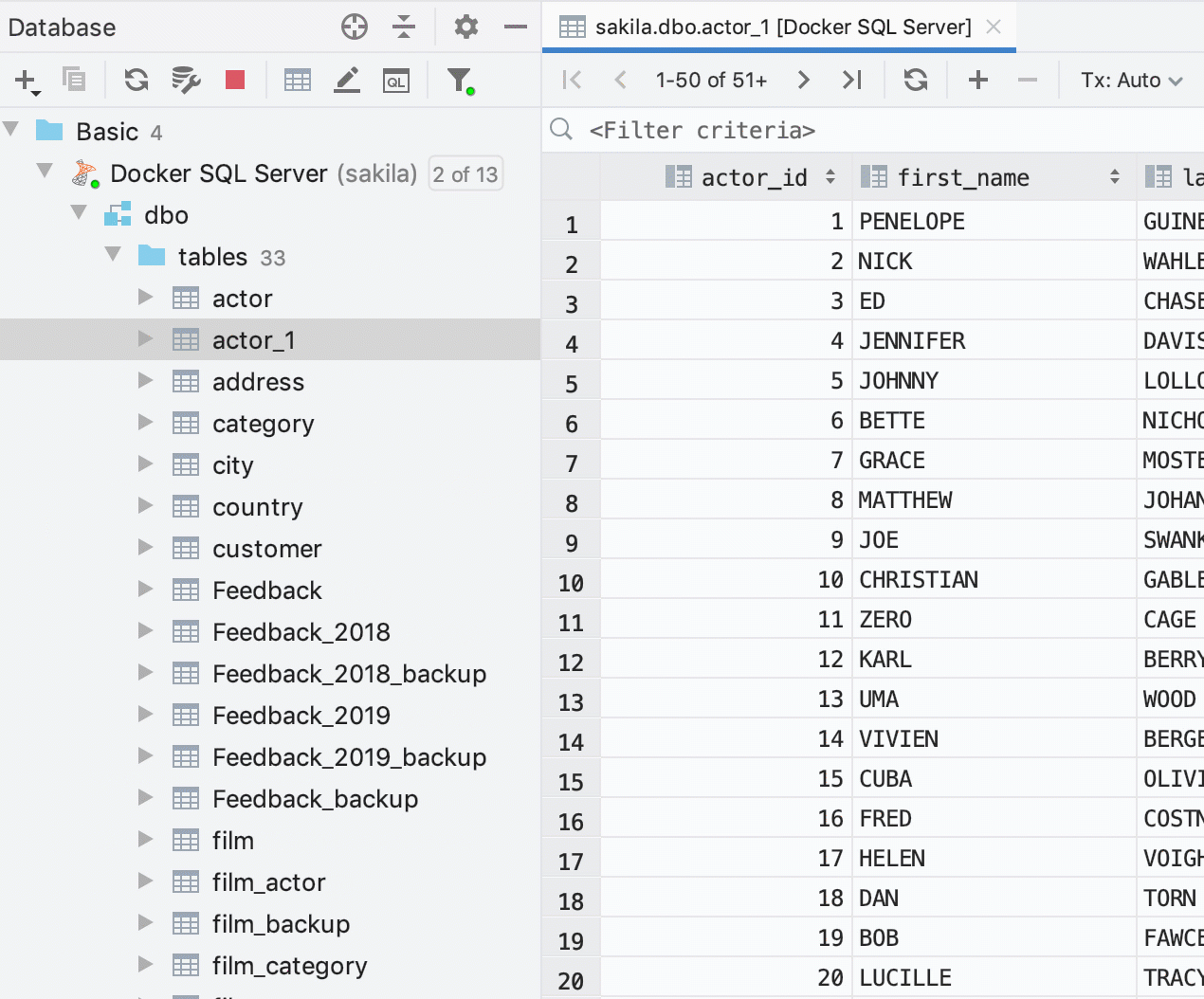
Arborescence de la base de données
Dans DataGrip 2019.2, il est possible de créer des sauvegardes rapides des tables. Il était déjà possible de copier des tables par glisser-déposer, mais cela ne fonctionnait pas lorsqu'il s'agissait d'une copie dans le même schéma. Or, cela pourrait être très utile, si vous aviez besoin de créer une sauvegarde rapide de la table avant toute manipulation cruciale de données. Dans DataGrip 2019.2, cela est donc désormais possible.
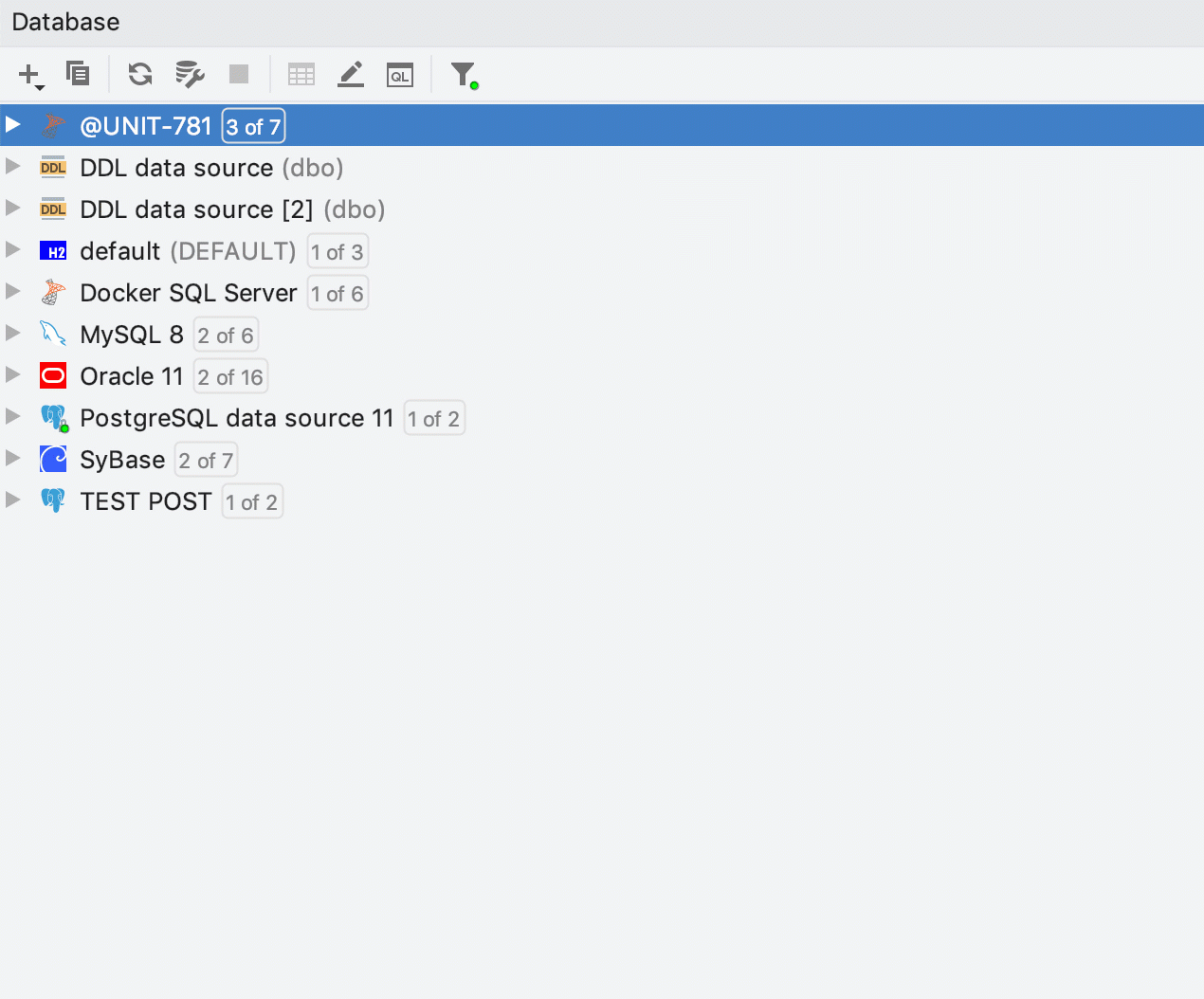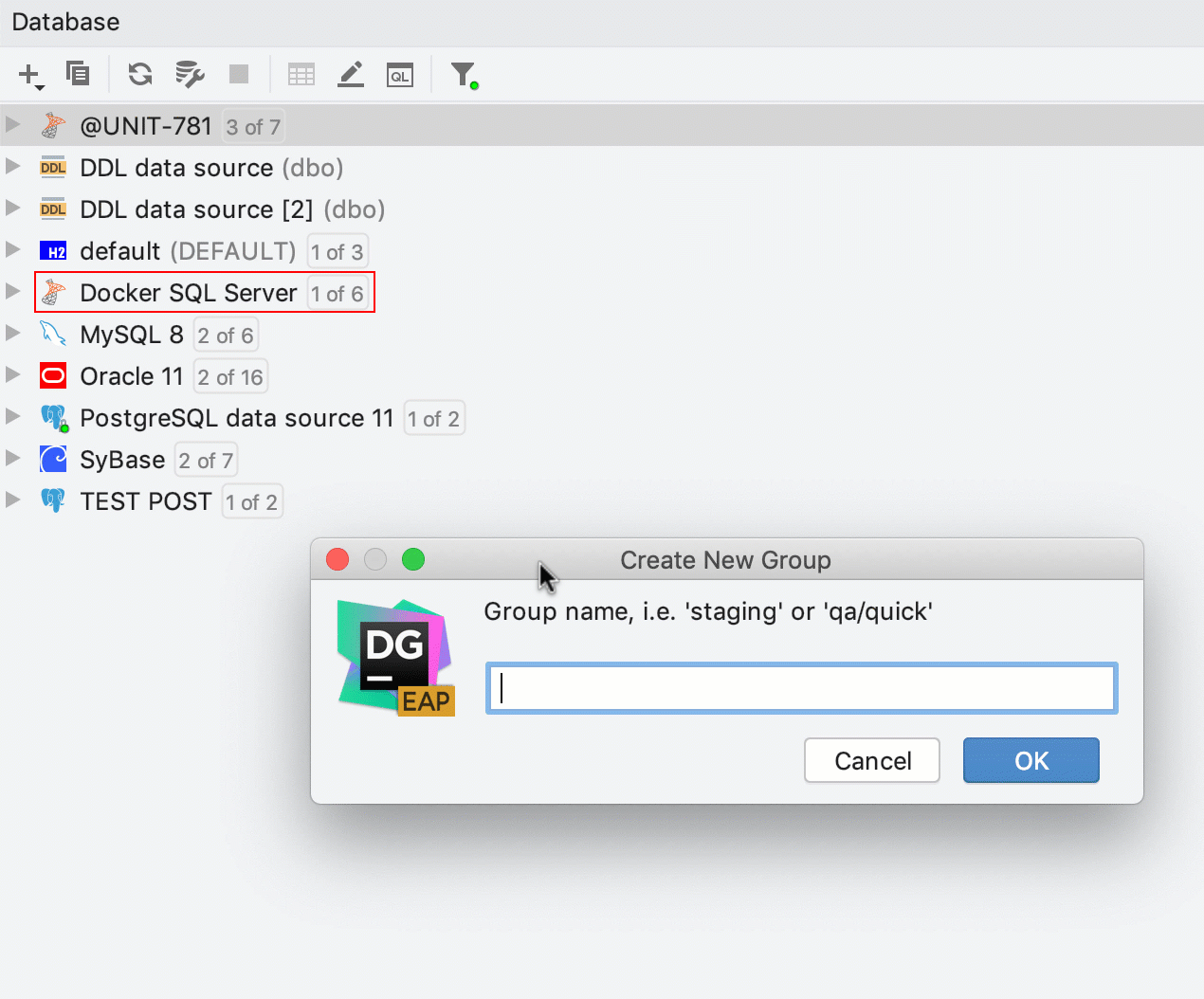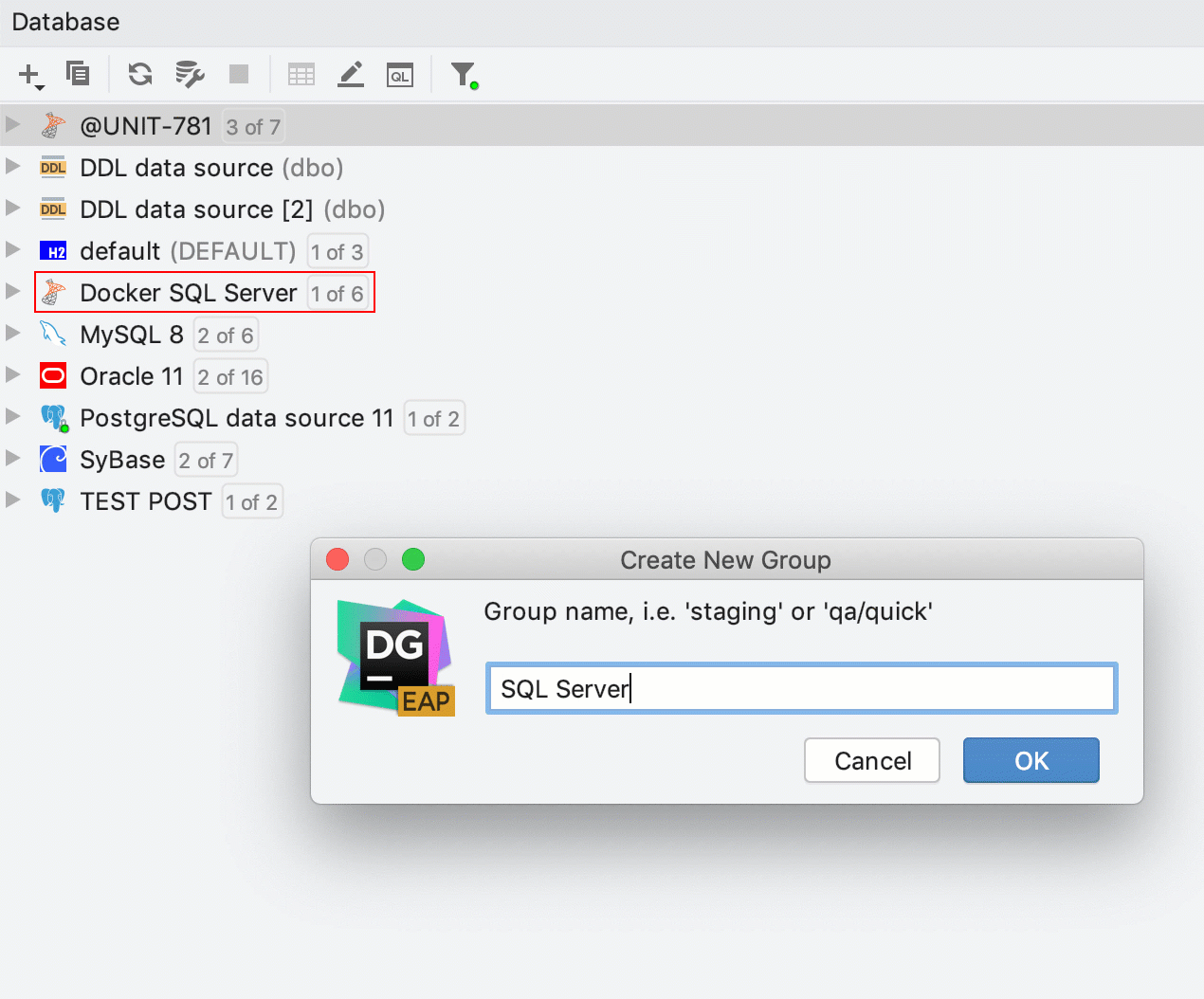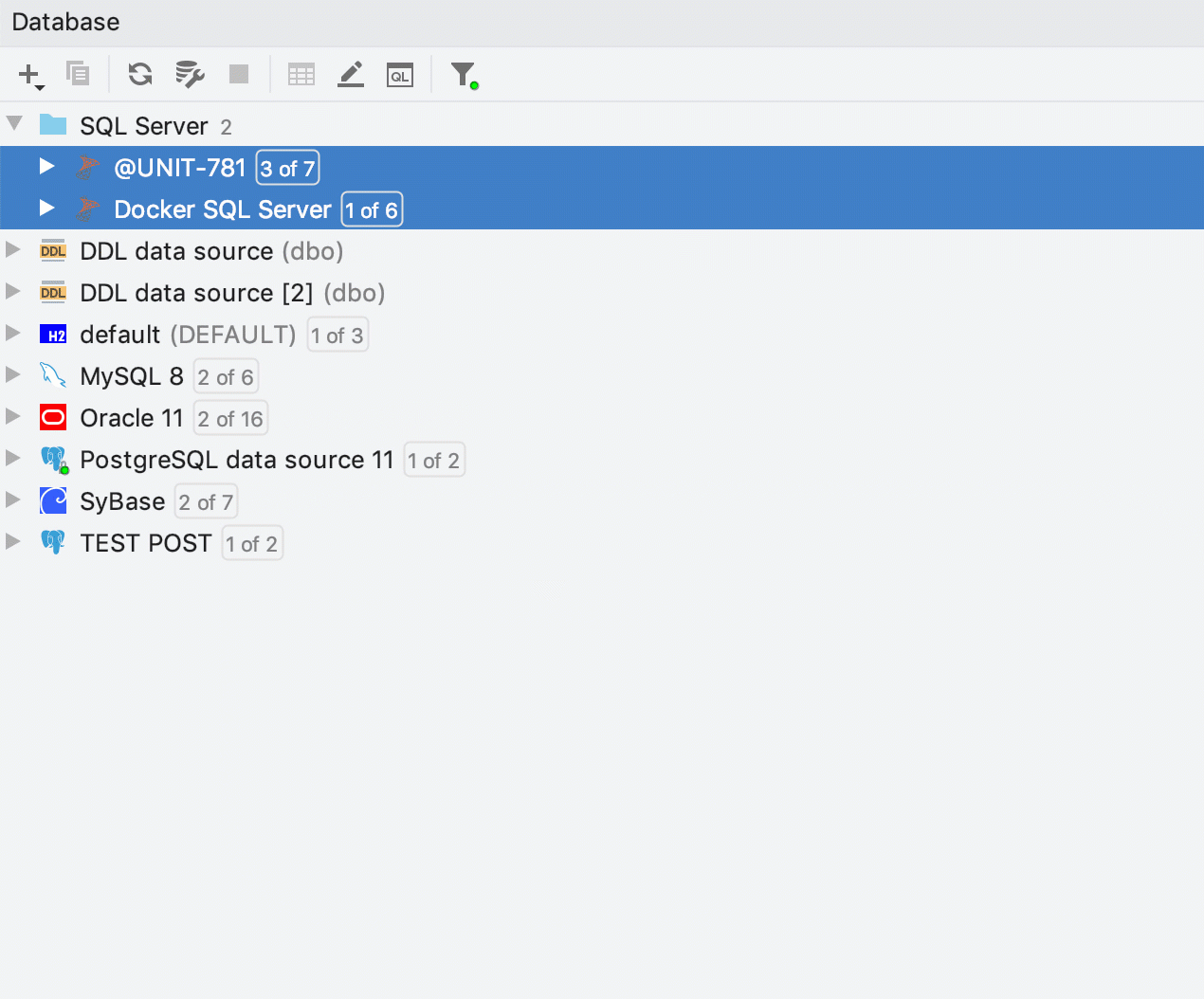
Maintenant, le glisser-déposer fonctionne également pour la création de groupes dans l'explorateur de bases de données. Pour créer un nouveau groupe, faites simplement glisser une source de données sur lautre. Pour placer la source de données dans un groupe existant, faites-la glisser sur le groupe.
Une nouvelle action appelée "Forcer l'actualisation" est disponible pour la source de données ou le schéma. Elle efface les informations de source de données que DataGrip met en cache et les actualise à partir de zéro.
Filtrage de source de données dans les recherches et la navigation
Lorsque vous essayez de localiser un objet via la fenêtre contextuelle GoTo, de nombreux objets similaires sont parfois présents dans la liste. Cela arrive fréquemment lorsque vous avez plusieurs miroirs (production, staging, tests, etc.). Dans DataGrip 2019.2, vous pouvez choisir où chercher : dans une source de données spécifique ou dans un groupe de source de données. Cela fonctionne également pour "Find In Path", ce qui est extrêmement utile lors de la recherche de code source dans les DDL des autres objets.
Assistance lors de l'écriture de code
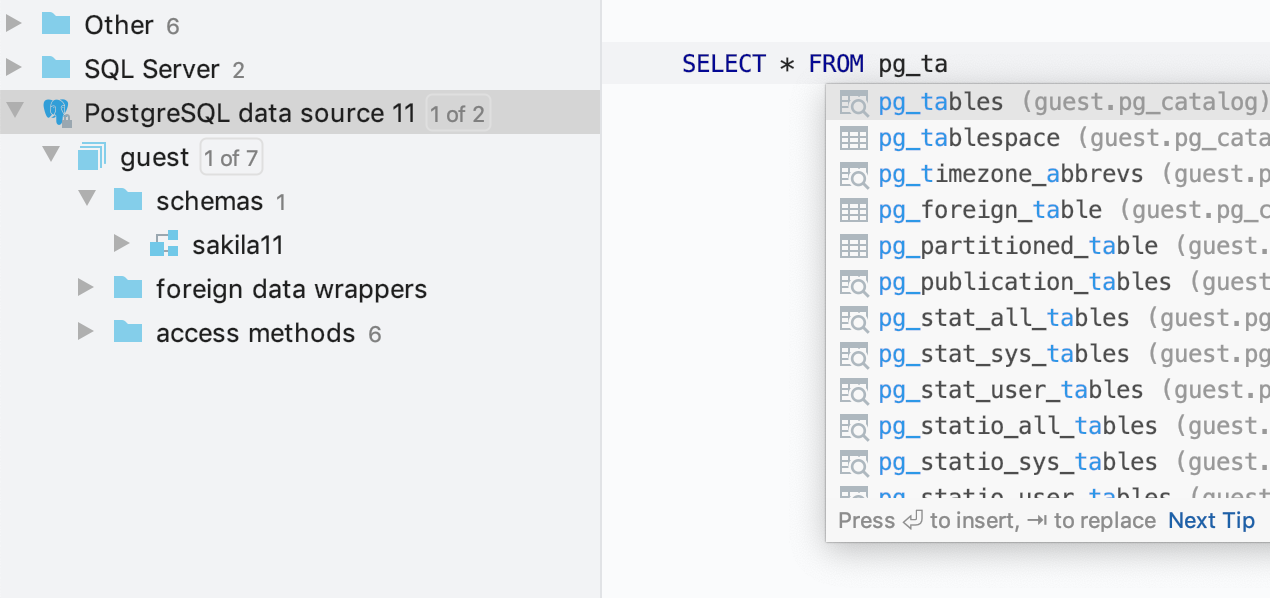
Ici, soulignons que la complétion et la résolution utilisent les objets des catalogues système. En effet, dans presque toutes les bases de données, il existe un catalogue système - un emplacement où un système de gestion de base de données relationnelle stocke des métadonnées de schéma, telles que des informations sur les tables et les colonnes, les fonctions intégrées, etc. Les objets de ces catalogues sont nécessaires pour fournir une assistance lors de l'écriture de code.
Cest bien de les avoir dans la complétion de code et le code qui les utilise ne doit pas être rouge. Mais auparavant, la seule façon davoir des catalogues système dans la complétion de code consistait à les ajouter à lexplorateur de bases de données. DataGrip récupérait des informations à leur sujet dans la base de données, ce qui prenait du temps. En outre, ils étaient visibles dans l'explorateur de base de données, ce qui n'est pas toujours nécessaire. Désormais, si vous ne les vérifiez pas, DataGrip ne va pas les afficher, mais utilisera les informations sur leurs objets dans l'assistance à l'écriture de code. Pour que cela soit possible, DataGrip utilise ses données internes sur les catalogues système pour chaque base de données.
JetBrains a aussi intégré les correctifs rapides (quick-fix) dans linfobulle dinspection. Si DataGrip sait comment résoudre un problème qui est mis en évidence, vous le saurez en survolant simplement l'avertissement. Vous pourrez alors le résoudre automatiquement en cliquant simplement sur un lien dans l'infobulle.
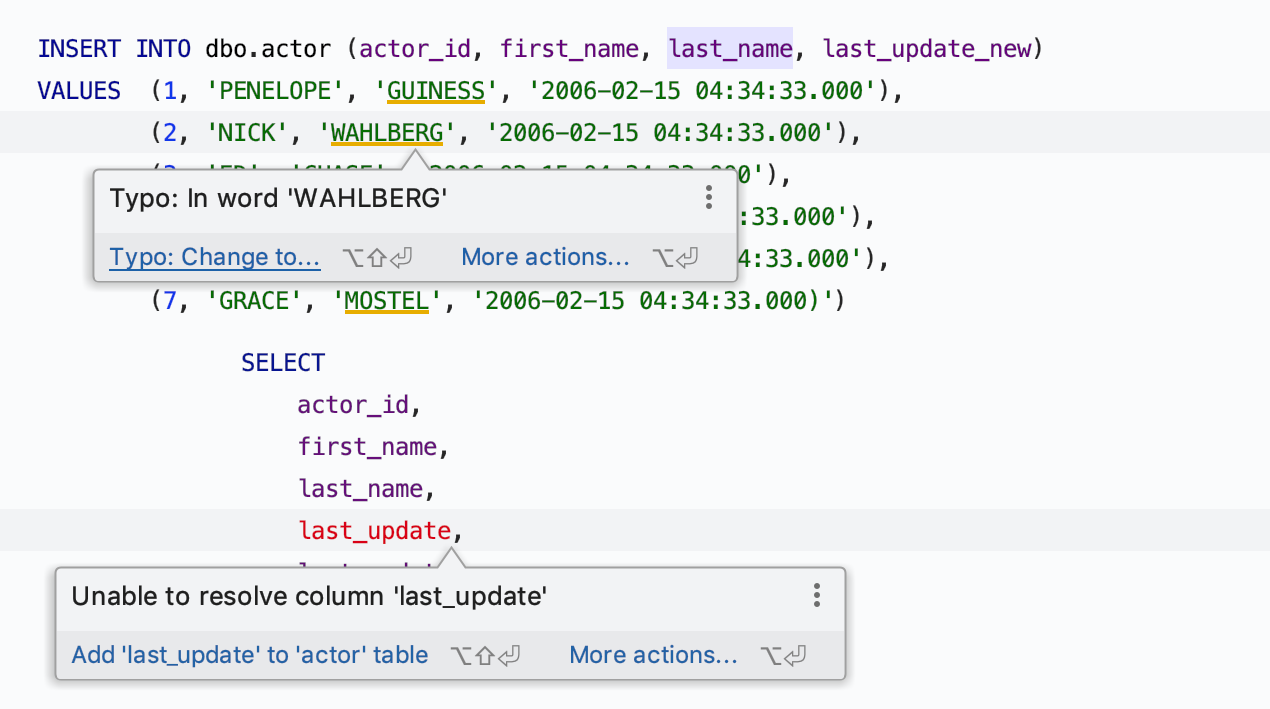
Toujours pour faciliter l'écriture de code, de nouvelles inspections, "Unnecessary usage of CASE" et "Possible truncation of the string" sont disponibles. La première permet de détecter les utilisations non nécessaires de CASE. Concrètement, lorsque vous utilisez des constructions CASE, DataGrip analyse si elles peuvent être transformées en constructions plus lisibles.

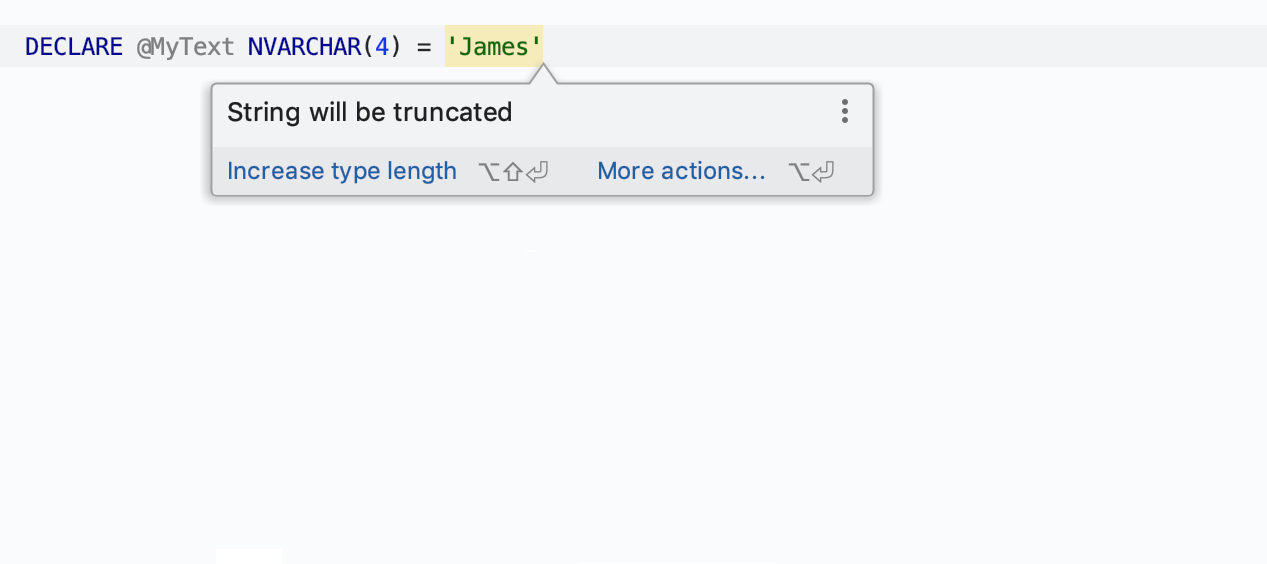
La deuxième vous avertit d'une possible troncature d'une chaine. L'EDI détecte en effet la longueur de la chaîne lors de l'attribution d'une valeur à la variable et vous avertit si elle sera tronquée.
Dans DataGrip 2019.2, JetBrains a également ajouté une action dintention supplémentaire, "Replace GROUP BY with DISTINCT", qui vous permet de convertir GROUP BY en DISTINCT si toutes les colonnes dune clause SELECT sont présentées dans une clause GROUP BY.

Éditeur de code
Il existe une nouvelle option permettant de contrôler le comportement de l'action "Move Caret to Next Word" (Déplacer le curseur au mot suivant). Le comportement par défaut de l'action a été modifié. Maintenant, DataGrip déplace le curseur à la fin du mot courant.
Voici comment se comportait l'action avant :
Et maintenant, voici comment l'action se comporte :
Pour changer le comportement des actions de déplacement du curseur, allez dans "Préférences / Paramètres > Editeur > Général".
Une nouvelle action "Select current statement" est également disponible. Comme son nom l'indique, elle permet de sélectionner l'instrument ne cours.

Aussi, si vous souhaitez améliorer la lisibilité des grands nombres, vous pouvez les "plier" avec le raccourci "Ctrl + Moins", comme vous pouvez le voir ci-dessous.

 Télécharger DataGrip 2019.2
Télécharger DataGrip 2019.2Voir aussi :
PyCharm : la version 2019.2 de l'EDI Python disponible avec une amélioration de l'expérience Jupyter Notebook et un support initial de Python 3.8 CLion 2019.2 disponible, l'EDI C/C++ de JetBrains apporte des améliorations pour le développement embarqué et un débogueur expérimental MSVC WebStorm 2019.2 disponible : tour d'horizon des nouveautés de l'EDI de JetBrains pour les développeurs JavaScript IntelliJ IDEA 2019.2 apporte des fonctionnalités en préversion de Java 13, des outils de profilage et bien plus encore La version 2019.2 de YouTrack, le logiciel de gestion de projet et de suivi des incidents est disponible et peut être désormais connecté à Bitbucket
Vous avez lu gratuitement 1 544 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.