


XXIV. EXERCICES▲
|
Préparés en collaboration avec Yann Vièmont Laboratoire PRiSM, UVSQ. |
Ces textes représentent un ensemble de sujets de partiels et d'examens écrits par Georges Gardarin et Yann Viémont soumis aux étudiants à Paris VI puis à Versailles entre 1980 et 2000. Nous nous excusons auprès de ces nombreux étudiants (ils sont aujourd'hui pour la plupart ingénieurs dans un domaine porteur) pour la difficulté et parfois le manque de clarté de certains de ces textes, mais les bases de données, ce n'est pas si facile…
Des versions de ces textes ont souvent été relues par des collègues que nous tenons ici à remercier, dont M. Bouzeghoub, M. Cheminaud, B. Finance, R. Gomez, M. Jouve, J. Madelaine, E. Métais, I. Paumelle, P. Pucheral, E. Simon, P. Testemale, J-M. Thévenin, P. Valduriez et K. Zeitouni.
Ces sujets ont parfois été repris comme texte de Travaux Dirigés (TD) et développés par ailleurs. Des corrigés de quelques-uns de ces exercices étendus et modifiés pourront être trouvés dans la série d'ouvrages Les Bases de Données en Questions aux éditions Hermès, par Mokrane Bouzeghoub, Mireille Jouve et Philippe Pucheral. Cependant, les annales qui suivent ont été adaptées et modernisées pour mieux correspondre aux chapitres qui précédent.
XXIV-1. DISQUES MAGNÉTIQUES (chapitres I et III)▲
Le parallélisme entre un traitement par l'unité centrale et une entrée-sortie (E/S) disque permet la prise en compte de nouvelles requêtes pendant l'exécution d'une requête plus ancienne. Ainsi, devant chaque unité d'échange, le système est amené à gérer des files d'attente de requêtes. Les requêtes en attente peuvent être planifiées afin de minimiser les temps d'E/S disques. Nous considérons une unité de disques inamovibles à tête mobile des plus courantes.
Soit une file d'attente composée des cinq instructions de lecture suivantes, arrivées dans cet ordre :
- Piste 20 - secteurs 11 à 14
- Piste 30 - secteurs 41 à 42
- Piste 40 - secteurs 40 à 43
- Piste 30 - secteurs 05 à 08
- Piste 53 - secteurs 03 à 07.
XXIV-1-1. Question 1▲
Rappelez le fonctionnement d'une E/S disque et calculez le temps nécessaire en fonction de la vitesse de rotation et du temps de déplacement de bras unitaire. Fixez les paramètres à des valeurs correspondant aux technologies courantes.
XXIV-1-2. Question 2▲
Quel est le temps nécessaire pour exécuter les requêtes en attente suivant leur ordre d'arrivée (stratégie FIFO) ?
XXIV-1-3. Question 3▲
Déterminez les quatre meilleures permutations possibles des requêtes minimisant le temps d'E/S disques. Parmi ces quatre séquences, quelle est la meilleure ? Pourquoi ?
XXIV-1-4. Question 4▲
Donnez le principe d'un algorithme permettant de trouver la séquence optimale. Quel doit être son temps de réponse maximal pour qu'il puisse être utilisé ?
XXIV-1-5. Question 5▲
Calculez le temps nécessaire pour exécuter les cinq instructions d'E/S en attente en choisissant à chaque fois d'exécuter la requête la plus proche des têtes de lecture-écriture.
XXIV-1-6. Question 6▲
L'utilisation de disques RAID permet d'accélérer les E/S disques. Discutez des différents types de RAID et de leur intérêt pour accélérer les cinq requêtes.
XXIV-2. MÉTHODES DE HACHAGE (chapitre III)▲
On considère un fichier haché de P paquets contenant N articles au total, décrivant des produits selon le format (Numéro, Nom, Type, Prix, Fournisseur, Quantité). Les articles sont composés de 80 octets en moyenne.
XXIV-2-1. Question 1▲
Discutez le choix de la taille du paquet.
Proposez quelques fonctions de hachage afin de déterminer le numéro de paquet à partir du numéro de produit. Discutez de l'intérêt de ces fonctions selon le mécanisme d'attribution des numéros de produits.
XXIV-2-2. Question 2▲
Lorsqu'un paquet est plein, un produit devant être inséré dans ce paquet est écrit en débordement. Proposez différentes solutions pour la gestion des débordements. Pour chacune d'elles, calculez le nombre moyen d'entrées-sorties nécessaires pour écrire un nouvel article et lire un article existant.
XXIV-2-3. Question 3▲
On utilise le hachage extensible. Rappelez l'algorithme d'écriture d'un nouvel article et de lecture d'un article. Calculez le nombre d'entrées-sorties nécessaires pour écrire un nouvel article et lire un article existant.
XXIV-2-4. Question 4▲
Même question avec le hachage linéaire.
XXIV-3. MÉTHODES D'INDEXATION (chapitre III)▲
Les méthodes d'accès indexées des systèmes actuels sont toutes basées sur les arbres B et B+. L'objectif de cet exercice est d'étudier plus en détail ces méthodes.
XXIV-3-1. Question 1▲
Rappelez la définition d'un arbre B et d'un arbre B+. Illustrez ces définitions en construisant un arbre B et un arbre B+ pour stocker l'alphabet dans des arbres d'ordre 2. Quel est l'intérêt d'un arbre B+ par rapport à un arbre B ?
XXIV-3-2. Question 2▲
Calculez le nombre de comparaisons de clés nécessaires à la recherche d'une lettre dans un arbre B et B+ d'ordre 2. Ce nombre est-il différent pour un arbre d'ordre 3 ?
Généralisez les résultats à un arbre d'ordre m contenant n clés.
XXIV-3-3. Question 3▲
Il est possible de comprimer les clés dans un arbre B ou B+ en enregistrant pour chaque clé seulement la différence par rapport à la précédente. Préciser alors le format de chaque entrée dans l'arbre B. Donnez les algorithmes de recherche et d'insertion d'une clé dans un arbre B ou B+ en prenant en compte la compression.
XXIV-3-4. Question 4▲
VSAM implémente les arbres B+ en essayant de les calquer à la structure des disques. Discutez de l'intérêt de cette approche et de ses inconvénients. Calculez le nombre d'entrées-sorties nécessaires pour lire un article dans un fichier avec un seul niveau d'index maître. Même question pour les insertions d'articles.
XXIV-3-5. Question 5▲
Une recherche dans un fichier simplement indexé par un arbre B sur une clé non discriminante (clé secondaire) peut être coûteuse. Pourquoi ? Proposez des approches pour réduire le temps d'entrées-sorties disques nécessaire.
XXIV-4. ARBRES B+ (chapitre III)▲
On désire étudier les propriétés des arbres B+ pour les clés alphabétiques, pour les attributs de type chaîne de caractères de longueur variable (varchar). On définit ici un arbre B+ un peu particulier comme suit :
- les articles sont tous stockés dans les feuilles ;
- lors d'un éclatement, la clé médiane est recopiée au niveau supérieur ;
- le nombre d'articles dans une feuille ou le nombre de couples clé/pointeur dans un sommet intermédiaire est contrôlé par le taux de remplissage (en octets) qui doit rester compris entre 50 % et 100 % ;
- la racine admet un taux de remplissage quelconque ;
- la racine est soit une feuille soit un sommet non-feuille qui possède alors au moins deux fils.
On notera que le taux minimal de remplissage n'est qu'à peu près de 50 % à cause des problèmes de parité du nombre des articles lors des éclatements et à cause de la longueur variable des articles.
On supposera que les pages font 50 octets, qu'un pointeur (sur un sommet) est codé sur 4 octets, que les clés sont de longueur variable, que les articles se composent de la clé + une information associée sur 10 octets + 2 octets qui servent de séparateurs et que les couples clé/pointeur n'utilisent qu'un séparateur. On négligera dans les calculs l'information de contrôle en tête des pages qui permet de connaître le nombre d'articles ou de couples clé/pointeur, etc.
Par exemple l'article de clé « Marcel » est représenté par « Marcel#xxxxxxxxxx# » soit 18 octets. Le couple clé/pointeur (« Marc », sommet yyyy) est représenté par « Marc#yyyy » soit 9 octets.
XXIV-4-1. Question 1▲
Donnez l'arbre obtenu en partant d'une racine vide après insertion des articles de clé :
{Marcel, Marius, Martine, Maurice, Marcelle, Maude, Marc, Marguerite, Mathilde, Maxime, Marielle, Martial, Mariette, Marina, Matthieu, Mattias} dans l'ordre indiqué.
XXIV-4-2. Question 2▲
Donnez l'arbre obtenu si la liste des articles est triée selon l'ordre des clés :
{Marc, Marcel, Marcelle, Marguerite, Marielle, Mariette, Marina, Marius, Martial, Martine, Mathilde, Matthieu, Mattias, Maude, Maurice, Maxime}.
XXIV-4-3. Question 3▲
Proposez une procédure de construction de l'arbre B+ par construction directe des feuilles et des sommets intermédiaires à partir d'un fichier trié des articles.
XXIV-4-4. Question 4▲
On remarque que dans un arbre B+ les clés dans les sommets non-feuilles ne servent que d'aiguilleurs dans la recherche d'un article de clé donnée. On utilise cette remarque pour augmenter le nombre de couples clé/pointeur dans les sommets non-feuilles en remplaçant les clés par un préfixe de ces clés.
Donnez la règle qui permet de déterminer le plus petit préfixe possible qui conserve la propriété d'aiguiller correctement la recherche dans l'arbre.
XXIV-4-5. Question 5▲
Donnez l'arbre obtenu en utilisant des préfixes par insertions répétées comme dans la question 1.
XXIV-4-6. Question 6▲
Discutez les avantages et les inconvénients de cette méthode pour de petits fichiers et pour de grands fichiers.
XXIV-5. UTILISATION D'INDEX SECONDAIRES (chapitre III)▲
Un index secondaire est un index sur une clé de recherche (dite clé secondaire) construit de telle sorte que l'information associée à la clé soit l'adresse de l'enregistrement (ou tuple en relationnel) et non pas l'enregistrement lui-même. Cette adresse peut être soit directement une adresse relative de tuple dans le fichier le contenant, soit indirectement la clé (dite primaire) primaire d'un autre index permettant de retrouver ce tuple. Dans ce dernier cas, que nous utiliserons ici, une recherche sur clé secondaire consiste à d'abord rechercher la clé secondaire dans l'index secondaire, à obtenir l'information associée c'est-à-dire la clé primaire, puis à rechercher le tuple dans l'index primaire à l'aide de la valeur trouvée.
Un tel index est dit non-plaçant, car les tuples correspondants à deux valeurs successives de clé secondaire dans l'index ne se trouvent pas en séquence dans le fichier les contenant, ni non plus en général dans les mêmes pages de disques (contrairement à l'index primaire dit plaçant).
Soit R (A, B, C, D, E) une relation à cinq attributs dont A est une clé unique. On suppose que la relation est placée, par un index primaire, sur l'attribut A en utilisant un arbre B+ à quatre niveaux (dont le dernier niveau contient les tuples).
Deux index secondaires sur C et E sont disponibles. Ces index sont également organisés en arbre B+. Chaque index secondaire est composé de trois niveaux.
R comprend 1 000 000 de tuples et donc autant de valeurs différentes pour A. Les tuples font en moyenne 100 octets, les pages de disques 1 Koctets. Avec un taux de remplissage de 75 %, le dernier niveau de l'arbre B+ occupe donc environ 130 000 pages de disque. Il y a 10 000 valeurs différentes pour C et 1 000 pour E. On suppose de plus que toutes les distributions des attributs X sont (1) uniformes entre une valeur MIN_X et MAX_X et (2) indépendantes.
XXIV-5-1. Question▲
Quels sont la meilleure méthode et le nombre correspondant d'entrées/sorties disques nécessaires pour répondre aux recherches suivantes :
- Q1. (A = "valeur")
- Q2. ("valeur" < A)
- Q3. (C = "valeur")
- Q4. (B = "valeur")
- Q5. ("valeur 1" < C < "valeur 2").
- Q6. (C = "valeur 1") ET (E = "valeur 2")
XXIV-6. OPTIMISATION ET INDEX SECONDAIRES (chapitre III)▲
La recherche dans les bases de données s'effectue selon des critères multiples, du type :
<critère simple> {AND | OR } <critère simple> …où chaque critère simple est lui-même du type :
<attribut> <comparateur> <valeur>Les comparateurs peuvent être =, <, >, ≥, ≤. Les expressions de AND et OR peuvent être encadrées de parenthèses pour indiquer les priorités.
Par exemple, on recherchera dans un fichier de vins tous les articles satisfaisant :
(CRU = "Volnay" OR CRU = "Chablis")
AND DEGRÉ ≥ 12 AND MILLÉSIME = 2000XXIV-6-1. Question 1▲
On suppose le fichier des vins indexés par un arbre B sur la clé secondaire DEGRÉ. Proposez un format d'entrée pour un tel index. Justifiez votre solution.
Les degrés étant nombreux car continus entre 0 et 20, comment peut-on réduire leur nombre ?
Proposez un algorithme permettant de répondre aux requêtes précisant DEGRÉ > $v, où $v désigne un réel compris entre 0 et 20.
XXIV-6-2. Question 2▲
Ce fichier est aussi indexé sur les clés secondaires CRU et MILLÉSIME. Proposez trois méthodes pour résoudre des requêtes du type CRU = $c AND MILLÉSIME = $m, l'une utilisant les deux index, les deux autres un seul ($c et $m sont deux constantes). Essayez d'estimer le coût en entrées-sorties de chacune d'elles. Donnez des heuristiques simples pour choisir l'une ou l'autre.
XXIV-6-3. Question 3▲
De manière générale, proposez un algorithme capable d'évaluer efficacement des recherches avec critères multiples conjonctifs (AND).
XXIV-6-4. Question 4▲
Étendre l'approche au cas de critères multiples connectés avec des AND et des OR.
XXIV-6-5. Question 5▲
Un fichier haché peut aussi être indexé selon plusieurs attributs. Comment peut-on améliorer l'algorithme précédent pour supporter aussi des fichiers hachés ?
XXIV-7. HACHAGE MULTI-ATTRIBUTS (chapitre III)▲
Le hachage multiattributs consiste à combiner plusieurs fonctions de hachage H1, H2, …, Hn sur des champs différents A1, A2, …, An des articles d'un fichier, ceci afin de calculer l'adresse virtuelle d'un paquet. En version statique simple, le numéro du paquet est simplement égal à H1(A1) || H2(A2) … Hn(An), où || désigne l'opérateur de concaténation. En version extensible, les bits de poids faible de cette chaîne peuvent être retenus pour adresser le répertoire des paquets. D'autres solutions plus sophistiquées sont possibles, par exemple en permutant sur les fonctions de hachage pour prélever des bits constituant l'adresse du répertoire. Dans la suite, on suppose un fichier haché statique avec adressage des paquets par concaténation simple des fonctions de hachage.
XXIV-7-1. Question 1▲
On désire placer un fichier de lignes de commandes de format (NC, NP, TYPE, QUANTITÉ, PRIX) par hachage multiattributs. NC désigne le numéro de commande, NP le numéro de produit et TYPE le type du produit. Sachant que 50 % des recherches se font sur NC, 20% sur NP et 30% sur le type de produit, proposez des fonctions de hachage optimum afin de placer un tel fichier dans 100 paquets.
XXIV-7-2. Question 2▲
Proposez un algorithme général pour répondre aux requêtes multicritères précisant deux des attributs hachés parmi les trois, par exemple NC et TYPE.
XXIV-7-3. Question 3▲
Généralisez l'algorithme pour traiter des requêtes multicritères avec AND et OR, comme vu à l'exercice précédent.
XXIV-7-4. Question 4▲
Les fichiers hachés peuvent aussi être indexés par des arbres B. Discutez des formats d'adresses d'articles intéressants pour gérer les index en conjonction au hachage. Intégrez les résultats de l'exercice précédent à l'algorithme de la question 3. En déduire un algorithme général pour traiter des requêtes multicritères sur des fichiers hachés sur plusieurs attributs et indexés.
XXIV-8. INDEX BITMAPS (chapitre III)▲
Les index bitmap sont adaptés aux attributs ayant un nombre limité de valeurs (a0, a1, …, an) pour un attribut A. Un index bitmap est une table de bits à deux dimensions. Le bit (i, j) est à 1 si le ie article du fichier à la valeur ai pour l'attribut A.
XXIV-8-1. Question 1▲
Précisez le format d'un index bitmap et des structures associées. Calculez la taille d'un tel index. Proposez des méthodes de compression pour un tel index.
XXIV-8-2. Question 2▲
Donnez les algorithmes d'insertion et suppression d'un enregistrement dans un fichier avec index bitmap.
XXIV-8-3. Question 3▲
Un index bitmap sur un attribut A est idéal pour accélérer des recherches sur critère de la forme :
A = $a0 OR A = $a1 OR … A = $anPrécisez l'algorithme de recherche.
XXIV-8-4. Question 4▲
On peut gérer plusieurs index bitmap pour un même fichier, sur des attributs A, B, etc. Précisez les types de critères pouvant être traités par des index bitmap.
XXIV-8-5. Question 5▲
On considère un fichier avec index bitmap et index secondaires sous la forme d'arbre B. Que doit référencer une entrée dans un index secondaire pour être combinable avec les index bitmap ? Donnez un algorithme général de recherche multicritères prenant en compte les index secondaires et les index bitmap.
XXIV-9. MODÈLE RÉSEAU (chapitre IV)▲
On désire faire circuler des camions encombrants dans une ville pour livrer un client. Soit le schéma suivant de la base de données urbaine dans le modèle réseau :
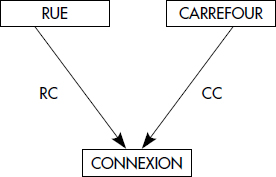
Une rue possède un nom, une longueur, une largeur minimum, un revêtement et un nombre de voies. Un carrefour possède un nom et un indicateur de présence de feu tricolore. Une connexion indique la présence éventuelle d'un sens interdit.
XXIV-9-1. Question 1▲
Donnez le schéma CODASYL correspondant à ce diagramme.
XXIV-9-2. Question 2▲
Donnez le graphe des occurrences correspondant au plan simplifié, à trois rues (X, Y, Z) et quatre carrefours (C1, C2, C3, C4), suivant :
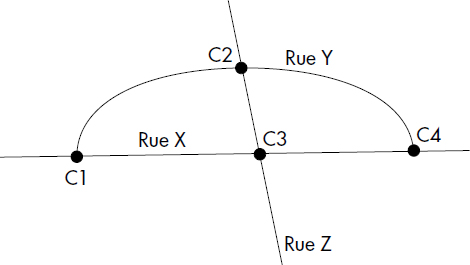
XXIV-9-3. Question 3▲
Donnez le programme en DML CODASYL permettant de trouver tous les carrefours avec feu de la rue Albert Einstein.
XXIV-9-4. Question 4▲
Donnez le programme en DML CODASYL permettant de trouver toutes les rues qui sont directement accessibles depuis la rue Albert Einstein (donc qui l'intersectent où s'y raccordent). Une rue n'est pas accessible si elle est en sens interdit.
XXIV-9-5. Question 5▲
Sachant que les poids lourds partent d'un dépôt situé dans la rue A, doivent rejoindre le client situé rue B et ne doivent circuler que dans des rues de largeur supérieure à 10 mètres, donner le programme en DML CODASYL et pseudocode qui recherche tous les itinéraires possibles en ne les donnant qu'une fois avec leur longueur et le nombre de feux. On précise que la partie pseudocode devra rester à un niveau de quelques blocs de commentaires et devra résoudre le problème de la détection des boucles.
XXIV-9-6. Question 6▲
Proposez un placement des types d'articles dans un ou plusieurs fichiers pour accélérer les performances. Donnez le nombre d'entrées-sorties disque nécessaires pour traiter la question 4.
XXIV-10. DU RÉSEAU AU RELATIONNEL (chapitre IV et VI)▲
On considère la base de données dont le schéma entité-association est représenté ci-dessous :
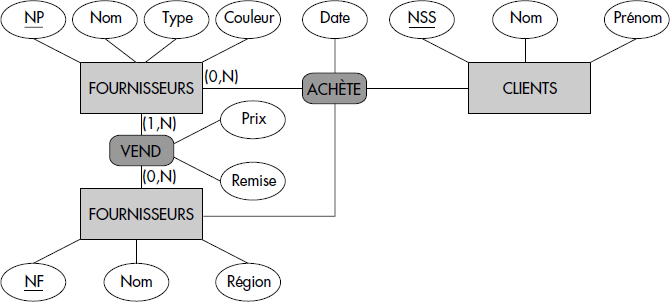
Cette base décrit des produits vendus par des fournisseurs à des clients.
XXIV-10-1. Question 1▲
Donnez le schéma réseau en DDL CODASYL correspondant au diagramme entité-association représenté figure 1. On précise que les entités PRODUITS et FOURNISSEURS sont rangées dans un même fichier FOU via le set VEND, alors que les instances de CLIENTS sont rangées dans le fichier CLI.
XXIV-10-2. Question 2▲
Écrire les programmes en DML CODASYL correspondant aux requêtes suivantes :
- Nom des fournisseurs vendant des produits de type « informatique ».
- Nom des clients ayant acheté de tels produits.
- Noms des produits et liste des fournisseurs associés ayant vendu au client de N°SS 153300017012.
- Chiffre d'affaires total réalisé avec le client Dupond Jules.
Utiliser du pseudo-Pascal ou pseudo-C si nécessaire.
XXIV-10-3. Question 3▲
Donnez un schéma relationnel pour la base de données représentée.
XXIV-10-4. Question 4▲
Exprimer en SQL les requêtes correspondant aux questions étudiées au 2.
XXIV-10-5. Question 5▲
Pour les schémas représentés, proposez un algorithme de traduction automatique de requête SQL de type restriction-projection-jointure en programme DML CODASYL. Pour cela, on traduira chaque requête en un arbre d'opérations de l'algèbre relationnelle optimisé de manière adéquate ; ensuite, on traduira des groupes d'opérateurs choisis en programmes DML avec du pseudo-PASCAL ou pseudo-C.
XXIV-10-6. Question 6▲
Étudiez le ré-engineering de la base réseau proposée en base relationnelle. Discutez des difficultés. Proposez une démarche.
XXIV-11. CALCULS DE DOMAINES ET DE TUPLES (chapitre V)▲
Soit le schéma entité-association représenté figure 1, modélisant une base de données décrivant des entités R, S et T reliées par les associations RS, ST1 et ST2. Tous les attributs sont de type entier. Les clés des entités sont soulignées ; elles correspondent simplement au premier attribut des entités. Les cardinalités minimum et maximum des associations sont indiquées sur les branches correspondantes. Ainsi, un tuple de R est associé par l'association RS à au moins 0 et au plus n tuples de S ; réciproquement, un tuple de S est associé par l'association RS à au moins 0 et au plus n tuples de T ; un tuple de T correspond par l'association ST1 à un et un seul tuple de S ; etc.
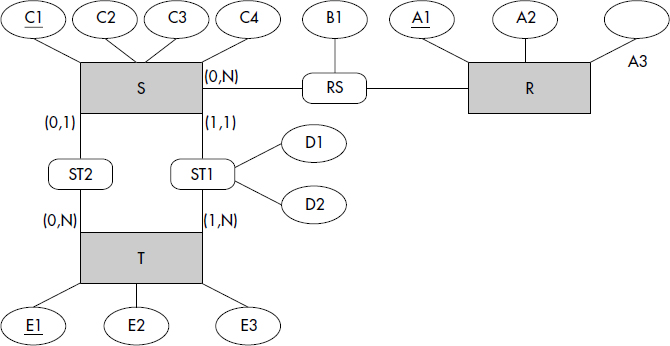
XXIV-11-1. Question 1▲
Donnez le schéma de la base de données relationnelle représentant directement ce diagramme entité-association (une entité générant une relation, une association générant une relation), avec les clés et les contraintes référentielles nécessaires.
XXIV-11-2. Question 2▲
Exprimer en calcul de tuples les requêtes suivantes :
- Donnez tous les attributs de S pour les tuples dont l'attribut C3 est compris entre 100 et 200.
- Donnez les attributs C1 et C2 de S, E1 et E2 de T tels que les tuples de S et T soient associés par un tuple de ST1 d'attribut D1 supérieur à 10.
- Même question, mais on souhaite en plus qu'il existe un tuple de R correspondant à chaque tuple de S sélectionné, via l'association RS, ayant un attribut A2 positif.
- Donnez les tuples de T associés par RS à tout tuple de R et au moins à un tuple de T par ST1 ou ST2.
XXIV-11-3. Question 3▲
Exprimer ces mêmes requêtes en calcul de domaines.
XXIV-11-4. Question 4▲
Exprimer ces mêmes requêtes en QBE.
XXIV-11-5. Question 5▲
Exprimer ces mêmes requêtes en SQL.
XXIV-12. ALGÈBRE RELATIONNELLE (chapitre VI)▲
Soit la base de données Sécurité Routière comprenant les tables :
PERSONNE (N°PERS, NOM, PRÉNOM, ADRESSE)
VÉHICULE (N°VEH, MARQUE, TYPE)
CONDUCTEUR (N°PERS, N°VEH, NBACC)
ACCIDENT (N°ACC, DATE, DÉPT)
VÉHPART (N°ACC, N°VEH, N°COND)
BLESSÉ (N°ACC, N°PERS, N°VEH, GRAVITÉ)En définissant le schéma, les hypothèses suivantes ont été faites :
- Les clés sont soulignées.
- Les relations PERSONNE et VÉHICULE ont les significations évidentes.
- La relation CONDUCTEUR associe les personnes et les véhicules et mémorise le nombre d'accidents auxquels a participé un conducteur donné au volant d'un véhicule donné.
- La relation ACCIDENT donne les informations globales d'un accident.
- La relation VÉHPART (véhicule participant) est définie de sorte que chaque véhicule impliqué dans un même accident donne un tuple avec le même numéro d'accident. L'attribut N°COND est le numéro de la personne conduisant le véhicule au moment de l'accident.
- La relation BLESSÉ indique tous les blessés d'un accident (un par tuple), y compris le conducteur si celui-ci a été blessé.
- L'attribut GRAVITÉ peut prendre les valeurs 'Bénigne', 'Légère', 'Sérieuse', 'Grave', 'Fatale'.
XXIV-12-1. Question 1▲
Exprimer sous la forme d'un arbre de calcul de l'algèbre relationnelle les requêtes suivantes :
- Donnez le nom, le prénom, la date de l'accident pour chaque personne blessée fatalement dans un accident du département 75 dans une voiture Citroën.
- Trouver les personnes qui ont été blessées dans tous les accidents où elles étaient conductrices.
XXIV-12-2. Question 2▲
Que retrouve l'arbre algébrique suivant ?
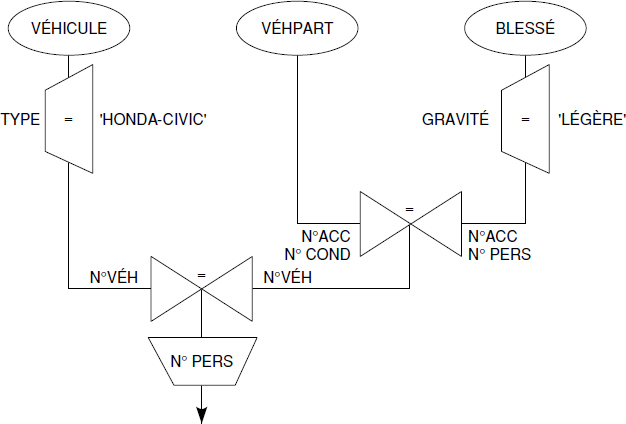
XXIV-12-3. Question 3▲
Calculez le coût en entrées/sorties disques de l'arbre de la question précédente avec les hypothèses suivantes :
- La relation VÉHICULE comporte 1 000 000 tuples dont 850 sont des Honda Civic ; elle est placée par hachage statique sur le N°VÉH ; elle possède un index secondaire sur le TYPE qui est un arbre B+ à 3 niveaux.
- Les index secondaires du système utilisé retournent la clé primaire (ou clé de placement) et non pas directement l'adresse physique.
- La relation VÉHPART comporte 100 000 tuples ; elle est placée sous forme d'arbre B+ sur le N°ACC (index primaire).
- La relation BLESSÉ comporte 40 000 tuples dont 10 000 sont des blessés légers ; elle est placée en séquentiel avec un facteur de blocage (moyen) de 20 tuples par page.
- Les jointures sont faites par l'algorithme des boucles imbriquées.
- Tous les résultats intermédiaires tiennent en mémoire centrale ; une page de mémoire correspond à un bloc de disque.
XXIV-12-4. Question 4▲
Que devient le coût des entrées/sorties si la mémoire est limitée à m pages ?
XXIV-13. OPÉRATEURS RELATIONNELS (chapitre VI)▲
On désire réaliser un évaluateur d'opérations de l'algèbre relationnelle sur un gestionnaire de fichiers avec index secondaires. Les opérations de l'algèbre relationnelle considérées sont les opérations classiques (restriction, projection, jointure, union, différence, intersection) avec en plus deux opérateurs spécialisés pour les calculs d'agrégats (groupage et calcul de fonction). Les expressions d'attributs sont aussi étendues avec les calculs arithmétiques (par exemple A*B+C est utilisable en argument de projection, A, B et C étant des attributs simples).
L'opérateur de groupage (nommé GROUP ou NEST) a pour argument un ensemble d'attributs X sur lequel est réalisé le groupage et un ensemble d'attributs à grouper Y. Il s'écrit formellement νX/Y(R). L'opération de groupage des attributs Y de la relation R sur les attributs X construit une relation non en première forme normale (NF2) de schéma XY ; pour chaque valeur de X, l'ensemble des valeurs de Y correspondant à cette valeur de X est répertorié. Par exemple, soit la relation :
|
R |
A |
B |
|---|---|---|
|
1 |
5 |
|
|
1 |
7 |
|
|
2 |
8 |
|
|
3 |
8 |
νA/B(R) est la relation suivante :
|
VA(B*)(R) |
A |
{B} |
|---|---|---|
|
1 |
{5,7} |
|
|
1 |
{8} |
|
|
2 |
{8} |
L'opérateur de calcul de fonction applique simplement une fonction sur ensemble à une colonne d'une relation valuée par un ensemble. Les fonctions considérées sont MIN, MAX, AVG, SUM, COUNT qui sont respectivement le minimum, le maximum, la moyenne, la somme et le compte. Par exemple, l'application de l'opérateur MINB à la relation précédente conduit au résultat suivant :
|
VA(B*)(R) |
A |
{B} |
|---|---|---|
|
1 |
{5,7} |
|
|
1 |
{8} |
|
|
2 |
{8} |
Afin d'illustrer, on considère une base de données décrivant un stock de jouets de type A, B, C ou D livrés par des fabricants en une certaine quantité à une certaine date. Le schéma de la base est le suivant :
JOUETS(NJ,NOMJ,TYPE,PRIX)
FABRIQUANTS(NF,NOMF,VILLE,ADRESSE)
LIVRAISONS(NF,NJ,DATE,QUANTITE)XXIV-13-1. Question 1▲
Exprimez en algèbre relationnelle étendue les questions suivantes sur la base de données des jouets :
- Donnez la liste des fabricants qui ont livré au moins un jouet de type A et de prix supérieur à 1 000 F ainsi que le nom des jouets correspondants livrés.
- Donnez la liste des fabricants qui n'ont pas livré de jouets.
- Donnez la somme des quantités livrées par chaque fabricant (caractérisé par NOMF et ADRESSE).
XXIV-13-2. Question 2▲
On se propose d'optimiser l'algorithme d'intersection de deux relations R1 et R2. Proposez trois algorithmes permettant de réaliser cet opérateur dans les cas sans index, respectivement basés sur :
- le produit cartésien des deux relations ;
- le tri des deux relations ;
- le hachage des relations avec tableaux de bits.
En supposant qu'il existe trois tampons d'une page en mémoire, que les relations comportent respectivement r1 et r2 pages (r1 < r2) et que la relation intersection est composée de i pages, calculez approximativement le coût en E/S de chaque algorithme. On supposera que les tableaux de bits tiennent en mémoire et qu'ils permettent d'éliminer un pourcentage b des tuples de la deuxième relation.
XXIV-13-3. Question 3▲
On se propose d'étudier l'algorithme de groupage d'une relation R. Proposez trois algorithmes permettant de réaliser cet opérateur dans les cas sans index, respectivement basés sur :
- la comparaison des tuples de la relation (proche du produit cartésien) ;
- le tri de la relation ;
- le hachage de la relation avec comparaisons internes aux paquets.
En supposant qu'il existe trois tampons d'une page en mémoire, que la relation comporte r pages et que la relation groupée est composée de g pages, calculez approximativement le coût en E/S de chaque algorithme.
XXIV-13-4. Question 4▲
Exprimer la question suivante en SQL sur la base de données des jouets :
Donnez les chiffres d'affaires de chaque fabricant (caractérisé par son NOMF et son ADRESSE) de poupées (NOMJ LIKE « Poupée »).
Exprimer cette question en algèbre relationnelle étendue.
Donnez un arbre d'opérateurs d'algèbre relationnelle optimisé permettant de calculer la réponse à cette question. On ajoutera pour cela l'opérateur de groupage (noté par un rectangle) aux opérateurs classiques.
XXIV-14. LANGAGES DE REQUÊTES (chapitres V, VI et VII)▲
Soit la base suivante décrivant un supermarché (les clés sont soulignées) :
RAYON (NOMR, ÉTAGE)
ARTICLE(RÉFÉRENCE, TYPE, DESCRIPTION, COULEUR)
DISPONIBILITÉ(NOMR, RÉFÉRENCE, QUANTITÉ)
EMPLOYÉ(NUMERO, NOME, SALAIRE, RAYON, RESPONSABLE)Les rayons identifiés par la clé NOMR sont situés à un étage donné. Les articles sont référencés par l'entier RÉFÉRENCE et décrit par un type, une description et une couleur. Ils sont disponibles en une certaine quantité à chaque rayon. Un employé travaille à un rayon et a pour responsable un autre employé. L'attribut responsable représente donc un numéro d'employé.
XXIV-14-1. Question 1▲
Proposez sous la forme d'un graphe un ensemble de clés étrangères pour cette base de données.
XXIV-14-2. Question 2▲
Exprimer en algèbre relationnelle puis en SQL les requêtes suivantes :
- références des articles de type 'électroménager' en rayon au second étage,
- nom des employés travaillant dans un rayon proposant des articles de type jouet pour une quantité totale supérieure à 1 000.
XXIV-14-3. Question 3▲
Exprimer en SQL les requêtes suivantes :
- nom des employés qui gagnent plus que leur responsable,
- étages qui ne vendent que des vêtements.
XXIV-14-4. Question 4▲
Exprimer en calcul de tuple puis en SQL la requête suivante :
- nom et salaire du responsable le mieux payé.
XXIV-15. LANGAGES DE REQUÊTES (chapitres V, VI et VII)▲
Soit le schéma relationnel suivant du Windsurf-Club de la Côte de Rêve (WCCR) :
SPOT (NUMSPOT, NOMSPOT, EXPOSITION, TYPE, NOTE)
PLANCHISTE (NUMPERS, NOM, PRENOM, NIVEAU)
MATOS (NUMMAT, MARQUE, TYPE, LONGUEUR, VOLUME, POIDS)
VENT (DATE, NUMSPOT, DIRECTION, FORCE)
NAVIGUE (DATE, NUMPERS, NUMMAT, NUMSPOT)La base du WCCR comprend cinq relations et les clés sont soulignées. Les SPOTS sont les bons coins pour faire de la planche, avec un numéro, leur nom, l'exposition principale par exemple 'Sud-Ouest', le type par exemple 'Slalom' ou 'Vague', et une note d'appréciation globale. Les PLANCHISTEs sont les membres du club et les invités, les niveaux varient de 'Débutant' à 'Compétition'. Le MATOS (jargon planchiste pour matériel) comprend la description des planches utilisées (pour simplifier les voiles, ailerons, etc., ne sont pas représentés). Le VENT décrit la condition moyenne d'un spot pour une date donnée. Enfin NAVIGUE enregistre chaque sortie d'un planchiste sur un spot à une date donnée avec le matos utilisé. Pour simplifier, on suppose qu'un planchiste ne fait qu'une sortie et ne change pas de matos ni de spot dans une même journée.
XXIV-15-1. Question 1▲
Indiquez les clés étrangères éventuelles de chaque relation.
XXIV-15-2. Question 2▲
Donnez les expressions de l'algèbre relationnelle qui permettent de calculer les requêtes suivantes :
- Nom des planchistes de niveau 'Confirmé' qui ont navigué le '20/07/99' sur un spot où le vent moyen était supérieur à force 4 sur une planche de moins de 2,75 m.
- Nom des planchistes qui ne sont pas sortis le '20/07/99'.
- Nom des planchistes qui ont essayé tous les types de planches de la marque 'FANA-BIC'. On suppose que tous les types sont dans la relation MATOS.
XXIV-15-3. Question 3▲
Donnez les expressions de calcul de tuples correspondant aux trois requêtes précédentes.
XXIV-15-4. Question 4▲
Donnez les ordres SQL correspondant aux requêtes suivantes :
- Nom des planchistes qui ont essayé tous les types de planches de la marque 'FANA-BIC'. On suppose que tous les types sont dans la relation MATOS.
- Pour chaque spot de la base, en indiquant son nom, donner le nombre de jours de vent au moins de force 4 pour l'année 94.
- Pour chaque marque de matériel représentée par au moins 10 planches, indiquer le nombre d'utilisateurs 'Confirmé' ou 'Expert'.
XXIV-16. LANGAGE SQL2 (chapitre VII)▲
Soit la base de données touristique suivante (les clés sont soulignées) :
STATION (NUMSTA, NOMSTA, ALTITUDE, REGION)
HOTEL (NUMHOT, NOMHOT, NUMSTA, CATEGORIE)
CHAMBRE (NUMHOT, NUMCH, NBLITS)
RESERVATION (NUMCLI, NUMHOT, NUMCH, DATADEB, DATEFIN, NBPERS)
CLIENT (NUMCLI, NOMCLI, ADRCLI, TELCLI)Les clients réservent des chambres dans des hôtels en station. On note que pour une réservation de plusieurs personnes (couple ou famille) un seul nom de client est enregistré. De plus, une réservation porte sur une seule chambre (pour une famille dans deux chambres, il faudra deux tuples dans réservation).
Exprimer en SQL les questions suivantes :
XXIV-16-1. Question 1▲
Donnez le nom des clients et le nombre de personnes correspondant pour les réservations de l'hôtel « Bellevue » à « Courchevel ».
XXIV-16-2. Question 2▲
Pour chaque station de Haute-Savoie, donner le nombre de lits en catégorie « trois étoiles ».
XXIV-16-3. Question 3▲
Pour chaque station de Haute-Savoie, donner le nombre de chambres réservées le samedi 11/02/95.
XXIV-16-4. Question 4▲
Quels sont les noms des hôtels de catégorie « deux étoiles » de « Méribel » qui sont complets la semaine du 12/02/2000 au 18/02/2000 ?
XXIV-16-5. Question 5▲
Quelles sont les régions dont toutes les stations sont à plus de 1500 m d'altitude ?
XXIV-16-6. Question 6▲
Quels sont les clients qui sont allés dans toutes les stations du « Jura » ?
XXIV-17. SQL2 ET LES JOINTURES (chapitre VII)▲
Soit la base de données suivante :
FREQUENTE (Buveur, Bar)
SERT (Bar, Vin)
AIME (Buveur, Vin)Tous les attributs sont de type chaînes de caractères notamment un bar, un buveur ou un vin.
Exprimer les questions suivantes en SQL :
- Donnez les buveurs qui fréquentent un bar servant du Beaujolais nouveau.
- Donnez les buveurs qui aiment au moins un vin servi dans un bar qu'ils fréquentent.
- Donnez les buveurs qui n'aiment aucun des vins servis dans les bars qu'ils fréquentent.
XXIV-18. SQL2 ET LES AGRÉGATS (chapitre VII)▲
On considère la base de données relationnelle représentée figure 1 correspondant approximativement au benchmark TPC/D. Elle stocke des commandes de numéro NUMCO passées par des clients de numéro NUMCLI décrits dans la table CLIENTS. Chaque commande est caractérisée par un état, un prix, une date de réception, une priorité et un responsable. Une commande est composée de lignes, chaque ligne étant caractérisée par un numéro NUMLIGNE et correspondant à un produit de numéro NUMPRO, commandé à un fournisseur NUMFOU. Les produits sont commandés en une certaine quantité pour un prix total PRIX, avec une remise en pourcentage (REMISE) et un taux de TVA (taxe). Les produits sont définis par un nom, une marque, un type et une forme, ainsi qu'un prix unitaire de base. Fournisseurs et clients sont des personnes décrites de manière standard. PRODFOURN est une table associative associant produit (NUMPRO) et fournisseur (NUMFOU) en indiquant pour chaque lien la quantité disponible et un commentaire libre.
COMMANDES (NUMCO, NUMCLI, ETAT, DATE, PRIORITÉ, RESPONSABLE)
LIGNES(NUMCO, NUMLIGNE, NUMPRO, NUMFOU, QUANTITÉ, PRIX, REMISE, TAXE)
PRODUITS (NUMPRO, NOM, MARQUE, TYPE, FORME, PRIXUNIT)
FOURNISSEURS (NUMFOU, NOM, ADRESSE, NUMPAYS, TELEPHONE, COMMENTAIRE)
PRODFOURN (NUMPRO, NUMFOU, DISPONIBLE, COMMENTAIRE)
CLIENTS (NUMCLI, NOM, ADRESSE, NUMPAYS, TELEPHONE, COMMENTAIRE)
PAYS (NUMPAYS, NOM, CONTINENT)Exprimer en SQL les questions suivantes :
- Calculez le prix TTC de chaque commande.
- Calculez le nombre de produits (rubriques) pour chaque fournisseur.
- Donnez les produits vendus par tous les fournisseurs.
- Donnez les produits vendus par tous les fournisseurs dans tous les pays.
- Donnez les noms et adresses des clients allemands ayant passé des commandes de produits de type « CD » à des fournisseurs français.
- Calculez les recettes effectuées au travers de ventes de fournisseurs à des clients du même pays, c'est-à-dire les recettes résultant de ventes internes à un pays, et ceci pour tous les pays d'Europe pendant une année commençant à la date D1.
XXIV-19. SQL2 ET OPTIMISATION (chapitres VII et X)▲
Soit le schéma relationnel de la Société Française d'Archéologie (fictive) :
OBJET (NUM-OBJ, DESCRIPTION, TYPE, DATATION, NUM-VILLE, NUM-SITE, NUM-MUSEE)
VILLE (NUM-VILLE, ANCIEN-NOM, NOM-ACTUEL)
MUSEE (NUM-MUSEE, NUM-VILLE, NOM)
SITE (NUM-VILLE, NUM-SITE, DESCRIPTION, CIVILISATION)
PUBLICATION (NUM-PUB, TITRE, DATE, EDITEUR)
AUTEUR (NUM-AUT, NOM, PRENOM)
COOPERATION (NUM-AUT, NUM-PUB)
REFERENCE (NUM-PUB, NUM-OBJ)Cette base gère des objets archéologiques et des publications sur ces objets. La relation OBJET décrit les objets proprement dits avec l'indication de leur type (par exemple « vase »), de leur datation qui est une année, du site où ils ont été découverts et du musée où ils se trouvent actuellement. La relation VILLE comprend deux noms pour simplifier (ce qui par exemple exclut le cas BIZANCE-CONSTANTINOPLE-ISTAMBUL). La relation SITE indique la ville à laquelle se rattache le site et un numéro qui est un numéro d'ordre pour cette ville : toutes les villes ont un site 1, un site 2, etc. La civilisation du site est une grande catégorie comme « romaine » ou « crétoise ». Les clés sont soulignées.
XXIV-19-1. Question 1▲
Exprimer en SQL les requêtes suivantes sur la base :
- Q1. Quelles sont les frises du troisième siècle ? Donnez leur numéro et leur description.
- Q2. Même question avec en plus le nom du musée où elles sont exposées.
- Q3. Noms et prénoms des auteurs d'ouvrage(s) référençant des objets de la civilisation Dorienne.
- Q4. Quelles statues sont exposées dans la ville où elles ont été découvertes ? Donnez le numéro et la description.
- Q5. Donnez le nom actuel des villes (s'il en existe) dont le nom actuel est le même que le nom ancien d'une autre ville.
- Q6. Donnez le nombre de statues trouvées dans chaque site de la civilisation phénicienne.
- Q7. Quels sont les sites d'Athènes qui ont fourni plus d'objets que le site 5 n'en a fournis ?
- Q8. Noms et prénoms des auteurs des ouvrages qui référencent tous les objets trouvés dans le site 2 de Thèbes.
XXIV-19-2. Question 2▲
Soit la requête SQL suivante :
SELECT P.TITRE, P.DATE
FROM PUBLICATION P, AUTEUR A, COOPERATION C,
REFERENCE R, OBJET O, MUSEE M
WHERE A.NOM = 'Vieille'
AND A.PRENOM = 'Pierre'
AND A.NUM-AUT = C.NUM-AUT
AND C.NUM-PUB = P.NUM-PUB
AND P.EDITEUR = 'Éditions archéologiques modernes'
AND P.NUM-PUB = R.NUM-PUB
AND R.NUM-OBJ = O.NUM-OBJ
AND O.TYPE = 'Mosaïque'
AND O.NUM-MUSEE = M.NUM-MUSEE
AND M.NOM = 'Le Louvre'Proposez deux arbres algébriques différents pour exécuter cette requête. Le premier arbre sera optimisé au mieux en utilisant les heuristiques de restructuration algébrique et le second sera le pire possible.
XXIV-19-3. Question 3▲
On suppose qu'il y a dans la base 10 000 publications, 100 éditeurs distincts, 1 000 auteurs de noms différents (pas d'homonymes), 2000 coopérations, 100 000 objets, 200 types d'objets différents, 1 000 000 de références et 100 musées de noms différents (pas d'homonyme).
On suppose de plus que toutes les distributions sont uniformes et indépendantes.
En prenant comme unité de coût la comparaison pour les sélections et les jointures, en supposant qu'il n'y a pas d'index et en admettant que toutes les jointures se font par produit cartésien, calculer le coût d'exécution des deux arbres que vous avez proposés.
XXIV-19-4. Question 4▲
Si vous étiez autorisé à créer un seul index pour accélérer cette requête, lequel choisiriez-vous ? Pourquoi ?
XXIV-20. INTÉGRITÉ DES DONNÉES (chapitre VIII)▲
L'objet de l'étude est de concevoir un composant logiciel capable de contrôler les contraintes d'intégrité lors des mises à jour d'une base de données relationnelle. Le composant doit être intégré dans un SGBD qui gère des relations différentielles. Lors de l'exécution des commandes de mise à jour (insérer, modifier, supprimer), deux relations différentielles sont associées à chaque relation R : la relation des tuples supprimés R- et celle des tuples insérés R+. Un tuple modifié donne naissance à deux tuples, l'un dans R-, l'autre dans R+. En fin de transaction validée, les tuples de R- sont enlevés de R et ceux de R+ ajoutés à R. Le SGBD réalise : R = (R - R-) ∪ R+.
En guise d'illustration, on utilisera la base composée des tables suivantes :
PLAGE (NP, NOMP, TYPE, REGION, POLLUTION)
NAGEUR (NN, NOM, PRENOM, QUALITE)
BAIGNADE (NN, NP, DATE, DUREE)La relation PLAGE modélise les plages de France, de nom NOMP, de type TYPE (galets, sable ou rocher) ayant un taux de pollution donné (attribut POLLUTION). La relation NAGEUR mémorise les nageurs de qualité excellente, bonne ou médiocre. La relation BAIGNADE décrit les bains effectués par les nageurs.
XXIV-20-1. Question 1▲
Définir en SQL2 les contraintes d'intégrité suivantes :
- La qualité d'un nageur est excellente, bonne ou médiocre (contrainte de domaine).
- Toute baignade a été effectuée par un nageur existant dans la base sur une plage existante (contraintes référentielles).
- Le type et la région d'une plage déterminent sa pollution de manière unique (dépendance fonctionnelle).
- La somme des durées des baignades d'un nageur par jour ne doit pas excéder deux heures.
XXIV-20-2. Question 2▲
Précisez quels types de contraintes d'intégrité peuvent être vérifiées après chaque ordre de mise à jour (INSERT, DELETE, UPDATE) ceux qui nécessitent d'attendre la fin de transaction.
XXIV-20-3. Question 3▲
Proposez des algorithmes pour traiter chaque type de contraintes d'intégrité, soient exécutés après la mise à jour, soient en fin de transaction. Montrer qu'il est possible de combiner les deux types de vérification.
XXIV-20-4. Question 4▲
Les contraintes avec agrégats comme la somme des durées des baignades sont coûteuses à vérifier à chaque mise à jour. Proposez une méthode basée sur des données redondantes afin de réduire ce coût.
XXIV-21. VUES ET TRIGGERS (chapitres VIII et IX)▲
Soit la base de données CINÉMA suivante :
FILM(NUMF, TITRE, DATE, LONGUEUR, BUDGET, RÉALISATEUR, SALAIRER)
GÉNÉRIQUE(FILM, ACTEUR, ROLE, SALAIRE)
PERSONNE (NUMP, FNOM, LNOM, DATENAIS, SEXE, NATIONALITÉ, ADRESSE, TÉLÉPHONE)
ACTEUR (NUMA, AGENT, SPÉCIALITÉ, TAILLE, POIDS)
CINÉMA(NUMC, NOM, ADRESSE, TÉLÉPHONE, COMPAGNIE)
PASSE (NUMF, CINÉMA, SALLE, DATEDEB, DATEFIN, HORAIRE, PRIX)
SALLE (CINÉMA, NUMS, TAILLEÉCRAN, PLACES)NUMF, NUMP, NUMA, NUMC, NUMS, sont des identifiants uniques (clés primaires) pour respectivement : FILM, PERSONNE, ACTEUR, CINÉMA, SALLE.
Tout nom de relation utilisé comme attribut est une clé étrangère qui renvoie à l'identifiant (clé primaire) de la relation correspondante, par exemple dans GÉNÉRIQUE, FILM correspond à NUMF de FILM et est défini sur le même domaine.
RÉALISATEUR dans FILM et NUMA dans ACTEUR sont définis sur le domaine des NUMP.
Le numéro de salle NUMS est un numéro local pour chaque cinéma (Salle 1, 2, 3, …).
XXIV-21-1. Question 1▲
Donnez la définition de FILM en SQL2 en précisant les contraintes de domaine, de clé (primaire ou candidate), et de clé étrangère.
XXIV-21-2. Question 2▲
Même question pour GÉNÉRIQUE si on suppose qu'un acteur peut jouer plusieurs rôles dans un même film.
XXIV-21-3. Question 3▲
Exprimer la contrainte généralisée suivante : « Le budget d'un film doit être supérieur à la somme des salaires des acteurs jouant dans ce film ».
XXIV-21-4. Question 4▲
Écrire un déclencheur qui met à jour automatiquement le numéro de film dans toutes les relations où il est utilisé si ce numéro est modifié dans la relation FILM.
On ajoute un attribut NBSALLES à FILM qui indique le nombre de salles où le film est actuellement visible.
XXIV-21-5. Question 5▲
Utiliser des déclencheurs pour gérer automatiquement ce nombre de salles.
XXIV-22. TRIGGERS ET VUES CONCRÈTES (chapitre VIII et IX)▲
On considère la base de données relationnelle :
PRODUITS (NP, NOMP, QTES, PRIXU)
VENTES (NP, NC, NV, QTEV)La relation produit décrit des produits en stock de numéro NP, de nom NOMP, en quantité QTES, dont le prix de vente unitaire est PRIXU. La relation VENTES décrit les ventes réalisées ; celles-ci sont numérotées par client. QTEV est la quantité vendue pour le produit NP au client NC lors de la vente NV. Pour simplifier, on supposera que les prix des produits ne changent pas.
XXIV-22-1. Question 1▲
Définir les vues VENTEPRO (NC,NP,NV, QTEV, PRIXU) et VENTETOT (NC, PRIXT) spécifiées comme suit :
- VENTEPRO donne pour chaque client, pour chaque produit et pour chaque vente la quantité de produit vendu et le prix unitaire du produit correspondant.
- VENTETOT donne pour chaque client le montant total en francs (PRIXT) des ventes effectuées.
On écrira les questions SQL permettant de créer ces vues à partir des relations de base.
Montrer que la vue VENTETOT peut être définie à partir de la vue VENTEPRO. Donnez sa définition en SQL à partir de VENTEPRO.
XXIV-22-2. Question 2▲
On introduit un opérateur partitionnement représenté par un rectangle préparant l'application du GROUP BY sur une relation, utilisable dans les arbres relationnels ; cet opérateur partitionne horizontalement la relation sur les attributs paramètres en effectuant simplement un tri sur ces attributs : il s'agit donc en fait d'un opérateur de tri. En addition, on permet l'usage de fonctions agrégats et arithmétiques dans les projections. Appliquées aux relations partitionnées suite à l'opérateur précédent, les fonctions agrégats accomplissent les calculs d'agrégats selon le dernier partitionnement effectué.
Donnez l'arbre relationnel optimisé permettant de retrouver les clients ayant acheté pour plus de 10 000 F de produits avec la liste des produits qu'ils ont achetés.
XXIV-22-3. Question 3▲
La modification de questions sur des vues (avec ou sans agrégat) ne permettant pas toujours d'optimiser, une autre méthode d'implantation de vues peut être basée sur la matérialisation de la vue comme une relation implantée sur disque (vue concrète). Le problème qui se pose est alors de mettre à jour la vue concrète lors des mises à jour des relations de base. Une technique possible consiste à générer des déclencheurs (triggers).
Exprimer en SQL les déclencheurs permettant de maintenir les relations VENTEPRO et VENTETOT lors de l'insertion d'un nouveau produit ou d'une nouvelle vente dans la base.
De manière générale, préciser les règles à générer pour maintenir une vue lors d'insertions dans une relation de base. On pourra considérer les cas suivants :
- La vue est sans agrégat, c'est-à-dire issue de projection, jointure et restriction des relations de base.
- La vue est avec agrégat.
XXIV-22-4. Question 4▲
Donnez les règles permettant de maintenir les relations VENTEPRO et VENTETOT lors d'une suppression d'un produit ou d'une vente dans la base.
De manière générale, préciser les règles à générer pour maintenir une vue sans agrégat, puis avec agrégat, lors d'une suppression dans une relation de base. Discutez selon les cas. Préciser les attributs qu'il est nécessaire de rajouter à la vue afin d'être capable de gérer correctement les suppressions.
XXIV-23. GESTION DE VUES VIRTUELLES (chapitre IX)▲
Une vue est un ensemble de relations déduites d'une base de données, par composition des relations de la base. Dans la norme SQL la notion de vue a été réduite à une seule relation déduite. Les mises à jour sont généralement limitées aux vues dont les projections portent sur une seule relation. Soit la base de données VITICOLE composée des relations suivantes :
BUVEURS (NB, NOM, PRENOM, VILLE, AGE)
VINS(NV, CRU, REGION, MILLESIME, DEGRE)
ABUS(NB, NV, DATE, QUANTITE)Celles-ci décrivent des buveurs identifiés par l'attribut numéro NB, des vins identifiés par l'attribut numéro NV et des consommations (ABUS) de vins identifiés par le numéro de buveur, le numéro de vin et la date de consommation.
XXIV-23-1. Question 1▲
Donnez les commandes SQL permettant de créer les vues suivantes :
BUVEURSB (NB, NOM, PRENOM, NV, DATE, QUANTITE)décrivant les buveurs de Beaujolais,
VINSB (NV, CRU, MILLESIME, DEGRE)décrivant les vins de Beaujolais bus par au moins un buveur.
Il est précisé que la vue VINSB est mettable à jour et que l'on souhaite la vérification des tuples insérés dans la vue par rapport au reste de la base.
XXIV-23-2. Question 2▲
Un utilisateur ayant droit d'interroger à partir des vues précédentes pose la question suivante :
« Donnez le nom des buveurs ayant bu du Beaujolais de millésime 1983 en quantité supérieure à 100, le même jour ».
Exprimez cette question telle que doit le faire l'utilisateur en SQL. Exprimez également la question modifiée portant sur les relations BUVEURS, VINS et ABUS que traitera le système.
XXIV-23-3. Question 3▲
De manière générale, proposez en quelques boîtes, sous la forme d'un organigramme, un algorithme permettant de transformer une question posée sur une vue en une question exprimée sur la base.
XXIV-23-4. Question 4▲
À partir de l'exemple, découvrir et énoncer quelques problèmes soulevés par la mise à jour à travers une vue référençant plusieurs tables :
- Ajout d'un tuple dans BUVEURSB ;
- Suppression d'un tuple dans BUVEURSB.
XXIV-24. LANGAGES ET OPTIMISATION (chapitres V, VI et X)▲
Soit la base de données composée des relations :
VILLE(NOMV, POP, NDEP)
DEPARTEMENT(NDEP, NOMD, REGION)
SPECIALITE(NOMV, NOMP, TYPE)où :
NOMV = nom de ville,
POP = population,
NDEP = numéro de département,
NOMD = nom de département,
REGION = nom de région,
NOMP = nom de produit,
TYPE = type de produitSoit l'expression algébrique suivante référençant les relations de cette base de données (![]() représente la jointure naturelle) :
représente la jointure naturelle) :
- ????NOMV,NOMP(σREGION="Auvergne"(σPOP>10000(VILLE
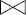 DEPARTEMENT SPECIALITE))) -
DEPARTEMENT SPECIALITE))) - - ????NOMV,NOMP(σNOMP="Fromage"(VILLE DEPARTEMENT SPECIALITE)))
XXIV-24-1. Question 1▲
Exprimez cette requête :
- en calcul relationnel de domaine ;
- en calcul relationnel de tuple ;
- en SQL.
XXIV-24-2. Question 2▲
Représentez la question sous forme d'un arbre d'opérations algébriques.
Proposez un arbre optimisé par restructuration algébrique pour cette question.
XXIV-24-3. Question 3▲
Soit v, d et s les tailles respectives en tuples des relations VILLE, DEPARTEMENT et SPECIALITE. En supposant l'uniformité des distributions des valeurs d'attributs, calculez une approximation de la taille du résultat de la question précédente en nombre de tuples. On pourra introduire tout paramètre supplémentaire jugé nécessaire.
XXIV-25. OPTIMISATION ET CHOIX D'INDEX (chapitre X)▲
Soit une base de données relationnelle composée des trois relations :
R1 (A1,A2,A3,A4,A5)
R2 (B1,B2,B3,B4,B5)
R3 (C1,C2,C3,C4,C5)On suppose pour simplifier qu'il n'existe pas d'index.
On considère la requête SQL :
SELECT A2,B3,C4
FROM R1, R2, R3
WHERE A1 = B1
AND B2 = C1
AND A3 = a
AND C3 = coù a et c désignent des constantes.
XXIV-25-1. Question 1▲
Donnez les arbres algébriques relationnels optimisés par les heuristiques classiques des BD relationnelles (descente des projections et restrictions) permettant d'exécuter cette question.
XXIV-25-2. Question 2▲
On choisit l'arbre qui effectue les jointures dans l'ordre R1 avec R2 puis avec R3. En considérant l'utilisation d'un algorithme de jointure par produit cartésien (boucles imbriquées), calculez le temps d'exécution en nombre d'E/S de cet arbre en fonction de la taille en page des relations R1, R2 et R3, du nombre moyen de tuples par page T, du nombre de valeurs distinctes et non distinctes des attributs utilisés. On supposera pour cela une distribution uniforme des valeurs d'attributs. Tout paramètre supplémentaire jugé nécessaire pourra être introduit.
XXIV-25-3. Question 3▲
Proposez un ensemble d'index plaçants et non plaçants optimaux pour la base de données et la question considérée.
Calculez alors le temps d'exécution de la question.
On pourra supposer pour simplifier que tous les index sont à deux niveaux et on négligera les temps de calcul.
XXIV-26. OPTIMISATION ET JOINTURES (chapitre X)▲
Soit une base de données relationnelle composée des tables suivantes :
R3 (U1, U2, U3)
R2 (V1, V2)
R1 (T1)U1 et V1 sont respectivement les clés uniques de R3 et R2. Tous les attributs sont des entiers tirés aléatoirement.
XXIV-26-1. Question 1▲
On considère alors la question :
SELECT U2,V2
FROM R1, R2, R3
WHERE R3.U1 = R2.V2 AND R2.V1 = R1.T1 AND R3.U3 = 100.Donnez tous les arbres relationnels effectuant les projections dès que possible permettant d'exécuter cette question.
XXIV-26-2. Question 2▲
Calculez le coût en nombre d'entrées-sorties des trois arbres effectuant la restriction d'abord dans le cadre d'un SGBD relationnel implémentant les restrictions par balayage et les jointures par parcours d'index ou boucles imbriquées. On précise qu'il existe un index sur les clés U1 de R3 et V1 de R2 et pas d'autre index. La taille de chaque relation R1, R2 et R3 est respectivement r1, r2 et r3. On supposera une distribution uniforme des valeurs d'attributs. Le nombre de valeurs distinctes d'un attribut est obtenu par la fonction DIST (par exemple, DIST(U2) est le nombre de valeurs distinctes de U2). Ce nombre peut être calculé.
XXIV-26-3. Question 3▲
Même question avec des jointures par hachage.
XXIV-26-4. Question 4▲
Avec un algorithme par hachage ou par boucles imbriquées, il est possible de commencer une jointure avant d'avoir fini la précédente. Expliquez ces algorithmes dits de type pipeline.
Dans quel cas est-il intéressant d'utiliser un algorithme de type pipeline ?
XXIV-26-5. Question 5▲
On généralise ce type de requêtes à N relations Rn, Rn-1, …, R1. Donnez la forme générale d'une requête. Calculez le nombre de plans possibles pour une telle requête.
XXIV-27. INDEX DE JOINTURES (chapitre X)▲
Soit deux relations U(U1, U2, …) et V(V1, V2, …). Afin d'accélérer les équi-jointures de U et V sur les attributs U1 et V1, on propose de gérer un index de jointures. Celui-ci peut être vu comme une relation UV(IDU, IDV) où IDU représente l'identifiant d'un tuple de U et IDV l'identifiant d'un tuple de V. Chaque tuple de UV donne donc les identifiants de deux tuples de U et V qui appartiennent à la jointure. Un identifiant est une adresse invariante qui permet de retrouver un tuple d'une relation en une entrée-sortie. Afin de permettre un accès rapide aux tuples de UV à partir des identifiants des tuples de U ou de V, l'index de jointure est organisé comme un fichier grille (Grid file) sur les attributs IDU et IDV (c'est-à-dire qu'il est organisé par hachage extensible multiattributs sur IDU et IDV, l'adresse de hachage étant obtenue en tournant sur les bits des deux fonctions de hachage sur IDU et sur IDV).
XXIV-27-1. Question 1▲
Proposez un algorithme en pseudocode, utilisant au mieux l'index de jointure, permettant de répondre à la question (bêta est une constante et il n'y a pas d'index sur V2) :
SELECT U.U2
FROM U, V
WHERE U1 = V1 AND V2 = betaCalculez le coût en nombre d'entrées-sorties de cet algorithme en fonction des tailles de U et de V (respectivement u et v tuples), de la sélectivité de la jointure (j), de la taille de l'identifiant (i octets), de la taille du paquet de hachage pour UV (1 paquet = 1 page de p octets) et du taux de remplissage moyen du paquet (dénoté t).
XXIV-27-2. Question 2▲
On suppose que le système gère un index de U sur U1 et de V sur V1 à la place de l'index de jointure. Détailler l'algorithme pour répondre à la question précédente en utilisant la jointure par index. Calculez le coût d'une telle jointure. On précise que :
- le nombre d'octets occupés par chaque valeur de U1 ou U2 est dénoté a ;
- le nombre de valeurs distinctes de U1 est DIST(U1), celui de U2 est DIST(U2) ;
- les index sont des arbres B+ à deux niveaux (feuille + racine).
Comparer à la solution index de jointure vue en 1.
XXIV-28. DU RELATIONNEL À L'OBJET (chapitre XI)▲
L'hôpital X a besoin de votre aide pour exprimer des requêtes sur leur base de données. On rappelle le schéma de leur base relationnelle :
SERVICE (CODE-S, NOM-S, BATIMENT, DIRECTEUR)
SALLE (CODE-S, NUM-SALLE, SURVEILLANT, NB-LITS)
EMPLOYEE (NUM-E, NOM-E, PRENOM-E, ADR, TEL)
DOCTEUR (NUM-D, SPECIALITE)
INFIRMIER (NUM-I, CODE-S, ROTATION, SALAIRE)
MALADE (NUM-M, NOM-M, PRENOM-M, ADR, TEL, MUTUELLE)
HOSPITALISATION (NUM-M, CODE-S, NUM-SALLE, LIT, DIAGNOSTIC)
SOIGNE (NUM-D, NUM-M)En définissant le schéma les hypothèses suivantes ont été faites :
- Les clés sont soulignées.
- Un service possède deux clés, CODE-S et NOM-S.
- Le directeur d'un service est un docteur identifié par son NUM-D.
- Le numéro de salle est local à un service (i.e. chaque service possède une salle numéro 1).
- Un(e) surveillant(e) est un(e) infirmier(ère) identifié(e) par son NUM-I.
- Docteurs et infirmiers(ères) sont des employés, NUM-D et NUM-I sont donc également des NUM-E et les tuples correspondants doivent exister dans EMPLOYEE.
- Un(e) infirmier(ère) est affecté(e) à un service et à un seul.
- Les docteurs ne sont pas affectés à un service particulier.
- La relation HOSPITALISATION ne concerne que les malades hospitalisés à l'état courant.
- Un malade non hospitalisé peut toujours être suivi par son (ses) médecin(s) comme patient externe.
XXIV-28-1. Question 1▲
Donnez en UML la définition d'un schéma objet équivalent à cette base relationnelle. Exprimez ce schéma en ODL.
XXIV-28-2. Question 2▲
Puisque DOCTEUR et INFIRMIER sont des EMPLOYEE, proposez un nouveau schéma objet utilisant l'héritage pour la base hospitalière.
XXIV-28-3. Question 3▲
Exprimez en OQL la requête suivante : « Nom et prénom des cardiologues soignant un malade Parisien (dont l'adresse contient 'Paris') dans le service de 'Chirurgie générale ».
XXIV-28-4. Question 4▲
Essayez de simplifier le schéma objet en introduisant des attributs multivalués. Proposez des requêtes OQL utilisant des collections dépendantes.
XXIV-29. BD OBJETS (chapitre XI)▲
La société REVE désire informatiser la gestion des pères Noël. Pour cela, elle a acquis un SGBD objet ou objet-relationnel, supportant le langage OQL ou SQL3 (au choix). L'application est décrite par les phases suivantes :
- Toute personne est caractérisée par un nom, un prénom, une date de naissance, et une adresse composée d'un nom de ville, d'un numéro et nom de rue, ainsi que d'une localisation géographique 2D (X,Y).
- Les pères Noël effectuent des tournées, au cours desquelles ils visitent des enfants.
- Les pères Noël sont des personnes (on ne peut même plus rêver), ainsi que les enfants.
- Une tournée est composée d'une liste d'enfants à visiter, chaque point correspondant à un ou plusieurs enfants.
- À chaque tournée est affectée une hotte contenant des jouets étiquetés par le nom et l'adresse des enfants. La société enregistrera aussi le prix de chaque jouet.
- La transaction Effectuée_Tournée consiste à parcourir une tournée et à ajouter à chaque enfant à visiter dans la tournée les jouets qui lui reviennent, par insertion dans l'association nommée « possède ».
Une ébauche de schéma UML de la base est représentée page suivante.
XXIV-29-1. Question 1▲
Discutez de l'intérêt de choisir un SGBD objet ou objet-relationnel. Effectuez un choix.
XXIV-29-2. Question 2▲
Complétez la représentation UML de la base en précisant les cardinalités des associations.
XXIV-29-3. Question 3▲
Définir le schéma de la base en C++. Bien lire le texte et la question 4 afin de prévoir les structures et méthodes capables d'y répondre.
XXIV-29-4. Question 4▲
Écrire des programmes C++ naviguant dans la base et répondant aux requêtes suivantes :
- Q1 : Nom du père Noël qui vous a visité et prix total des jouets que vous avez reçus à Noël (on suppose que vous êtes un enfant).
- Q2 : Distance parcourue par le père Noël Georges Gardarin et liste des jouets distribués.
- U1 : Mettre à jour la base par enregistrement d'une nouvelle tournée pour un père noël donné.
XXIV-30. BD OBJETS (chapitre XI)▲
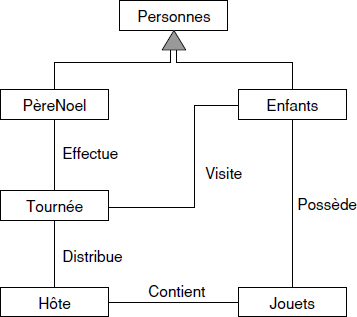
Soit le schéma entité / association page suivante.
Il correspond au suivi de pièces entrant dans la composition de modèles d'avion d'une compagnie aéronautique. On remarque que cette association ternaire ne peut pas être décomposée, car (1) une même pièce peut être utilisée dans plusieurs avions, (2) un ou plusieurs ingénieurs sont responsables du suivi de cette pièce et (3) le ou les ingénieurs responsables sont définis de façon différente pour chaque modèle où une pièce particulière est utilisée.
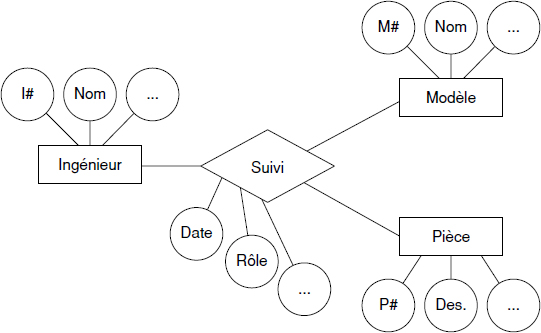
XXIV-30-1. Question 1▲
Proposez une représentation objet de ce schéma en utilisant UML. Discutez les propriétés de votre représentation. Donnez la définition en ODL correspondante.
XXIV-30-2. Question 2▲
Écrire les méthodes nécessaires pour faire une affectation d'une pièce à un modèle d'avion avec l'indication de la liste des ingénieurs chargés du suivi. Les méthodes seront écrites en Smalltalk, C++ ou Java persistant (ODMG) ou en pseudocode pour ceux qui ne sont pas à l'aise avec les concepts de l'un de ces langages objet. Attention à l'encapsulation.
XXIV-30-3. Question 3▲
Certaines pièces sont en fait des modules composés d'autres pièces ou d'autres modules. Proposez une modification du schéma pour Pièce.
XXIV-30-4. Question 4▲
Écrire une méthode qui donne la liste de tous les ingénieurs impliqués dans le suivi d'un module, soit directement soit au titre d'un composant. On pourra utiliser la méthode prédéfinie union de la classe générique Set qui prend un autre Set en paramètre.
XXIV-31. ALGÈBRE D'OBJETS COMPLEXES (chapitre XI)▲
Une algèbre d'objets complexes permet d'exprimer des requêtes sur une base de données objet sous forme d'expressions algébriques. Elle résulte en général d'une extension de l'algèbre relationnelle.
XXIV-31-1. Question 1▲
Rappelez les extensions nécessaires à l'algèbre relationnelle pour exprimer les requêtes objet. Proposez des exemples génériques de requêtes illustrant chaque extension.
XXIV-31-2. Question 2▲
Soit une succession de classes T1, T2, …, Tn reliées par des associations [M-N] via des attributs de rôle nommés A, B, …, X, comme représenté ci-dessous :

Quels algorithmes proposeriez-vous pour traiter efficacement la requête SQL3 de parcours de chemins :
SELECT *
FROM C1, C2, … Cn
WHERE C1.A = OID(C2)
AND C2.B = OID(C3)
…
AND Cn-1.X = OID(Cn) ?On pourra aussi exprimer cette requête en OQL.
XXIV-32. ODMG, ODL ET OQL (chapitre XII)▲
On considère une base de données géographiques dont le schéma est représenté de manière informelle ci-dessous :
REGIONS (ID CHAR(5), PAYS STRING, NOM STRING, POPULATION INT, carte GEOMETRie)
VILLES (NOM STRING, POPULATION INT, REGION ref(REGIONS), POSITION GEOMETRie)
FORETS (ID CHAR(5), NOM STRING, carte GEOMETRie)
ROUTES (ID CHAR(4), NOM STRING, ORIGINE ref(VILLES), EXTREMITE ref(VILLES), carte GEOMETRIE)Cette base représente des objets RÉGIONS ayant un identifiant utilisateur (ID), un pays (PAYS), un nom (NOM) une population et une carte géométrique. Les objets VILLES décrivent les grandes villes de ces régions et sont positionnés sur la carte par une géométrie. Les forêts (FORETS) ont un identifiant utilisateur, un nom et une géométrie. Les routes (ROUTES) sont représentées comme des relations entre villes origine et extrémité ; elles ont une géométrie.
Une géométrie peut être un ensemble de points représentés dans le plan, un ensemble de lignes représentées comme une liste de points ou un ensemble de surfaces, chaque surface étant représentée comme un ensemble de lignes (en principe fermées). Sur le type GEOMETRIE, les méthodes Longueur, Surface, Union, Intersection et DRAW (pour dessiner) sont définies.
XXIV-32-1. Question 1▲
Proposez une définition du schéma de la base en ODL.
XXIV-32-2. Question 2▲
Exprimer les questions suivantes en OQL :
- Q1. Sélectionner les noms, pays, populations et surfaces des régions de plus de 10 000 km2 et de moins de 50 000 habitants.
- Q2. Dessiner les cartes des régions traversées par la RN7.
- Q3. Donnez le nom des régions, dessinez régions et forêts pour toutes les régions traversées par une route d'origine PARIS et d'extrémité NICE.
XXIV-32-3. Question 3▲
Rappelez les opérations d'une algèbre d'objets complexes permettant d'implémenter le langage OQL. Donnez les arbres algébriques correspondants aux questions Q1, Q2 et Q3.
XXIV-33. SQL3 (chapitre XIII)▲
On considère une base de données composée des entités élémentaires suivantes (les clés sont soulignées lorsqu'elles sont simples) :
CLIENT
NoCl = Numéro du client,
Nom = Nom du client,
Rue = Numéro et rue du client,
Ville = Ville d'habitation du client,
CP = Code postal du client,
Région = Région d'habitation du client.
FOURNISSEUR
NoFo = Numéro du fournisseur,
Nom = Nom du fournisseur,
Rue = Numéro et rue du fournisseur,
Ville = Ville d'habitation du fournisseur,
CP = Code postal du fournisseur,
Région = Région d'habitation du fournisseur.
COMMANDE
NoCo = Numéro de commande,
NoCl = Numéro du client,
Date = Date de la commande,
Resp = Nom du responsable de la suivie de la commande.
LIGNE
NoCo = Numéro de commande,
NoPro = Numéro du produit,
NoLi = Numéro de ligne dans la commande,
Qtté = Quantité de produit commandé,
Prix = Prix total Toutes Taxes Comprises de la ligne,
PRODUIT
NoPro = Numéro du produit,
Nom = Nom du produit,
Type = Type du produit,
PrixU = Prix unitaire Hors Taxe,
NoFo = Numéro du fournisseur.On se propose d'étudier le passage en objet-relationnel de cette base de données et l'interrogation en SQL3. Pour cela, les questions suivantes seront considérées :
- Noms, types des produits et adresses des fournisseurs offrant ces produits.
- Noms des clients ayant commandé un produit de type « Calculateur ».
- Noms des fournisseurs et des clients habitant une région différente, tels que le fournisseur ait vendu un produit au client.
- Chiffre d'affaires toutes taxes comprises (somme des prix TTC des produits commandés) de chacun des fournisseurs.
XXIV-33-1. Question 1▲
Proposez un schéma UML pour cette base de données. On ajoutera les méthodes appropriées pour illustrer. On supprimera tous les pointeurs cachés (clés de jointures) qui seront remplacés par des associations. Définir ce schéma directement en SQL3, en utilisant des références et des collections imbriquées.
XXIV-33-2. Question 2▲
Exprimer en SQL3 les questions (a), (b), (c) et (d).
XXIV-33-3. Question 3▲
Comparer l'implémentation objet-relationnelle avec une implémentation directe en relationnel.
XXIV-33-4. Question 4▲
Reprendre les questions 1, 2 et 3 en utilisant ODL et OQL à la place de SQL3. Comparer les solutions.
XXIV-34. INTERROGATION D'OBJETS (chapitres XII, XIII et XIV)▲
Reprendre la base de données de la société RÉVE concernant les pères Noël, vue ci-dessus.
XXIV-34-1. Question 1▲
Définir cette base en ODL puis en SQL3.
XXIV-34-2. Question 2▲
Exprimer les requêtes suivantes en OQL puis SQL3 :
- Q1 : Nom du père Noël qui vous a visité et prix total des jouets que vous avez reçus à Noël (on suppose que vous êtes un enfant).
- Q2 : Distance parcourue par le père Noël Georges Gardarin et liste des jouets distribués.
XXIV-34-3. Question 3▲
Pour chacune des questions précédentes, proposez un arbre algébrique optimisé permettant de l'exécuter.
XXIV-34-4. Question 4▲
Rappelez la définition d'un index de chemin. Proposez deux index de chemins permettant d'accélérer l'exécution des questions Q1 et Q2.
XXIV-35. OPTIMISATION DE REQUÊTES OBJET (chapitre XIV)▲
Soit la base de données objet dont le schéma est représenté ci-dessous. Elle modélise des compagnies dont les employés sont des personnes. Ceux-ci possèdent 0 à N véhicules. Les doubles flèches représentent des attributs de liens de type listes de pointeurs.
XXIV-35-1. Question 1▲
Exprimer en OQL les questions suivantes :
- Q1 : ensemble des numéros de sécurité sociale et noms de personnes âgées de plus de 40 ans possédant au moins un véhicule de couleur rouge.
- Q2 : liste des noms de compagnies employant des personnes de plus de 40 ans possédant une voiture rouge.
XXIV-35-2. Question 2▲
Donnez un arbre d'opérations d'algèbre d'objets complexes optimisé par heuristique simple permettant d'exécuter la question Q2.
XXIV-35-3. Question 3▲
La jointure de deux classes C1 et C2, telles que Personnes et Voitures reliées par une association orientée multivaluée du type A—>>C1 peut être réalisée par un algorithme de parcours de pointeurs ou de jointure sur comparaison d'identifiant classique. Nous les appellerons « jointure avant JV » (par pointeur) et « jointure arrière JR » (par valeur). Détailler ces deux algorithmes en pseudocode.
XXIV-35-4. Question 4▲
On constate que la jointure de N classes reliées par des associations peut être réalisée par un seul opérateur de jointure n-aire, traversant le graphe en profondeur d'abord, appelé ici DFF. Détailler cet algorithme en pseudocode.
XXIV-35-5. Question 5▲
En dénotant page(Ci) et objet(Ci) le nombre respectif de pages et d'objets d'une classe Ci, par fan(Ci, Cj) le nombre moyen de pointeurs par objet de Ci vers Cj, en supposant un placement séquentiel sans index des objets, calculez le coût de chacun des algorithmes JR, JV et DFF. On pourra introduire d'autres paramètres si nécessaire.
XXIV-36. RÉCURSION ET ALGÈBRE RELATIONNELLE (chapitre XV)▲
Soit le schéma relationnel suivant :
PERSONNE (NUMÉRO, NOM, PRÉNOM, EMPLOI, PÈRE, MÈRE)PÈRE et MÈRE sont des clés étrangères sur la relation PERSONNE elle-même, ce sont donc des numéros de personne. Cette relation permet donc de représenter un arbre généalogique complet.
XXIV-36-1. Question 1▲
Donnez l'arbre algébrique correspondant à la requête : quels sont les enfants de M. Martin, de numéro 152487.
XXIV-36-2. Question 2▲
Donnez l'arbre algébrique correspondant à la requête : quels sont les petits-enfants de M. Martin, de numéro 152487.
XXIV-36-3. Question 3▲
Donnez l'arbre algébrique étendu correspondant à la requête : quels sont les descendants de M. Martin, de numéro 152487.
Pour cette dernière question on étendra les arbres algébriques de la façon suivante :
- un nœud supplémentaire de test permettra de spécifier un branchement conditionnel ;
- une boucle dans l'arbre sera autorisée ;
- un test pourra porter sur le résultat de l'opération précédente, par exemple (résultat = vide ?).
Attention à la condition d'arrêt du calcul.
XXIV-37. DATALOG ET MÉTHODES NAÏVES (chapitre XV)▲
XXIV-37-1. PARTIE 1▲
Soit le programme DATALOG :
- p1(X,X) ← p2(X,Y)
- p2(X,Y) ← p3(X,X), p4(X,Y)
et la base de données :
- p3(a,b), p3(c,a), p3(a,a), p3(c,c), p4(a,d), p4(a,b), p4(b,c), p4(c,a).
XXIV-37-1-1. Question 1▲
Donnez une expression relationnelle équivalente à ce programme pour le calcul des faits instances des prédicats p1(X,X) et p2(X,Y).
XXIV-37-1-2. Question 2▲
Donnez les faits instanciés de symbole de prédicat p1 déduits de ce programme et de la base de données.
XXIV-37-2. PARTIE 2▲
Soit le programme DATALOG :
- anc(X,Y) ← par(X,Y)
- anc(X,Y) ← anc(X,Z), par(Z,Y)
la base de données :
- par(baptiste,léon), par(léon,lucie), par(janine,léon), par(étienne,cloé),
- par(lucie,cloé), par(baptiste,pierre), par(janine,pierre), par(pierre,bernard),
- par(bernard,nicolas), par(bernard,lucien), par(bernard,noémie), par(lucien,éric).
et la requête :
- ? anc(bernard,Y)
XXIV-37-2-1. Question 1▲
Calculez les réponses à cette requête en appliquant la méthode naïve. Donnez les faits déduits à chaque itération.
XXIV-37-2-2. Question 2▲
Même question avec la méthode semi-naïve.
XXIV-37-2-3. Question 3▲
Écrire le programme modifié obtenu par la méthode des ensembles magiques.
Évaluez ce programme modifié sur la base, en montrant à chaque itération les faits déduits, et en précisant pour chaque fait déduit, par quelle règle il a été déduit.
XXIV-38. OPTIMISATION DE RÈGLES LINÉAIRES (chapitre XV)▲
On considère la base de données relationnelle :
EMPLOYE (NSS, NSER, NOM, SALAIRE)
SERVICE (NSER, NCHEF)NSS est le numéro de sécurité sociale de l'employé, NSER son numéro de service et NCHEF le numéro de sécurité sociale du chef.
XXIV-38-1. Question 1▲
Écrire un programme DATALOG calculant la relation :
DIRIGE(NSSC, NSSD)donnant quel employé dirige directement ou indirectement quel autre employé (le numéro de sécurité sociale NSSC dirige le numéro de sécurité sociale NSSD), ceci pour tous les employés.
XXIV-38-2. Question 2▲
Transformer le programme DATALOG obtenu à la question 1 en appliquant la méthode des ensembles magiques pour trouver les employés dirigés par Toto.
XXIV-38-3. Question 3▲
Modifier le programme trouvé à la question 1 pour calculer la relation
DIRIGE(NSSC, NSSD, NIVEAU)NIVEAU est le niveau hiérarchique du chef (1 chef direct, 2 chef du chef direct, etc.). Dans quel cas ce programme a-t-il un modèle infini ?
XXIV-38-4. Question 4▲
Donnez le graphe Règle-But et le graphe d'opérateurs relationnels correspondant à la question ? DIRIGE(Toto, x, 2) pour le programme trouvé en 3.
XXIV-38-5. Question 5▲
Écrire en DATALOG avec ensemble la question permettant de calculer la table
STATISTIQUE (NSER, CHEF, SALMAX, SALMIN, SALMOY)donnant pour chaque service, le nom du chef, le salaire maximum, le salaire minimum et le salaire moyen, ceci pour tous les services dont le salaire minimum dépasse 7 000 F.
XXIV-39. DATALOG ET RÈGLES REDONDANTES (chapitre XV)▲
Soit une base de données relationnelle composée de trois relations binaires B1, B2 et B3. Le but de l'exercice est d'optimiser le programme DATALOG suivant pour une question précisant le premier argument de R :
R(x,y) ← B1(x,y)
R(x,y) ← B3(x,z),R(z,t), B2(t,u), R(u,y)
R(x,y) ← R(x,v), B3(v,z), R(z,t), B2(t,u), R(u,y)On considère donc la question ? R("a",y), où a est une constante.
XXIV-39-1. Question 1▲
En utilisant les ensembles magiques, donnez le programme de règles transformées permettant de calculer la réponse à cette question.
XXIV-39-2. Question 2▲
Simplifier le programme obtenu par élimination des règles redondantes. Peut-on proposer une méthode générale permettant d'éviter de transformer des règles redondantes ?
XXIV-40. DATALOG ET OBJETS (chapitre XV)▲
On considère une base de données décrivant des lignes de chemin de fer dont le schéma est représenté figure 1. Cette base représente des objets VILLES ayant un nom (NOM) une population (POPULATION) et une carte géométrique (PLACE). Certains objets villes sont reliés par des tronçons de voies ferrées de type 1 (normal) ou 2 (T.G.V.) représentés par une géométrie et ayant une longueur (LONG) exprimée en km. On précise que l'identifiant de tout objet est obtenu par la méthode OID() ; celle-ci peut donc être vue comme un attribut implicite calculé au niveau de chaque classe.
CLASS VILLES (NOM STRING, POPULATION INT, PLACE GEOMETRIE)
CLASS TRONCONS (ID CHAR(4), TYPE INT, ORIGINE Obj(VILLE),
EXREMITE obj(VILLE), CARTE GEOMETRIE)Une géométrie peut être un ensemble de points représentés dans le plan, un ensemble de lignes représentées comme une liste de points ou un ensemble de surfaces, chaque surface étant représentée comme un ensemble de lignes (en principe fermées). Sur le type GEOMETRIE, les méthodes LONG, UNION, INTERSECTION et DRAW (pour dessiner) sont définies. LONG est supposée calculer la longueur d'une géométrie en km.
XXIV-40-1. Question 1▲
Donnez un programme DATALOG avec fonctions (utiliser en particulier les fonctions OID et DRAW) permettant de générer et tracer tous les parcours allant de la ville de nom A à la ville de nom B en parcourant moins de K km.
Discutez de l'optimisation de ce programme.
XXIV-40-2. Question 2▲
On désire calculer le coût d'un billet de train. Le coût est proportionnel au nombre de km parcourus. Il existe des billets normaux, des billets réduits, des billets T.G.V., et des billets T.G.V. réduits. La majoration sur les lignes T.G.V. est un coût de réservation initial plus un coût proportionnel à la longueur du trajet. La réduction est un pourcentage du prix appliqué au seul coût proportionnel à la distance parcourue. Proposez une organisation en classes et sous-classes pour les billets de train. Programmer en pseudo C++ une méthode TARIF qui calcule le prix de chaque billet. On précise qu'il est possible d'appeler une méthode d'une classe (qui peut être une superclasse) par la syntaxe classe::méthode (…).
XXIV-40-3. Question 3▲
Proposez une intégration de la méthode TARIF dans le programme réalisé à la question 1 afin de calculer le prix de chaque itinéraire de moins de x km permettant d'aller de A à B et de choisir le moins coûteux.
XXIV-41. CONTRÔLE DE CONCURRENCE (chapitre XVI)▲
Soit une base composée de 4 granules A, B, C, D et une exécution de 6 transactions T1 à T6. Les accès suivants ont été réalisés sur les granules (Ei signifie écriture par la transaction i et Lj lecture par la transaction j du granule indiqué) :
A : E2 E3 L5
B : L2 L4 L1
C : E5 L1 L3 E4
D : L6 L2 E3XXIV-41-1. Question 1▲
Dessiner le graphe de précédence. Que peut-on en conclure ?
XXIV-41-2. Question 2▲
On suppose que les demandes se font dans l'ordre global suivant :
E2(A) L2(B) L6(D) E5(C) E3(A) L5(A) L1(C) L2(D) L3(C) E4(C) E3(D)
L4(B) L1(B)Aucune transaction n'a relâché de verrous. L'algorithme utilisé est le verrouillage deux phases. Donnez le graphe d'attente. Que se passe-t-il ?
XXIV-41-3. Question 3▲
On rappelle que pour l'algorithme d'estampillage multiversion, les accès doivent être effectués dans l'ordre des estampilles des transactions, sauf les lectures qui peuvent se produire en retard. Une lecture en retard obtient la version qu'elle aurait dû lire si elle était arrivée à son tour. Les écritures en retard provoquent par contre un abandon de transaction.
Toujours avec l'ordre des accès de Q2, que se passe-t-il en estampillage multiversion ?
XXIV-41-4. Question 4▲
Pour gérer le multiversion, on suppose que l'on dispose d'une table en mémoire pouvant contenir 100 000 versions avec les estampilles correspondantes (pour l'ensemble des granules). De plus on conserve sur disque la dernière version produite de chaque granule.
On se propose de modifier l'algorithme d'estampillage multiversion de la façon suivante : chaque nouvelle version d'un granule mis à jour est écrite sur disque tandis que la version précédente est recopiée dans la table en mémoire. Cette table est gérée comme une file circulaire : chaque nouvelle version entrée chasse la version la plus ancienne (tous granules confondus). Lors d'une lecture, on recherche dans la table (ou sur disque) la version nécessaire si elle est disponible. Une lecture peut donc échouer et conduire à un abandon.
Donnez en pseudocode les algorithmes LIRE et ÉCRIRE correspondants.
XXIV-42. CONCURRENCE SÉMANTIQUE (chapitre XVI)▲
Soit une classe C++ persistante Réel définie comme suit :
class Réel: Pobject {
private:
Réel Valeur;
public:
operator+…;
operator*…
};Les actions de base indivisibles pour le contrôle de concurrence à étudier sont les opérations sur objets, c'est-à-dire + et * sur l'exemple.
On considère trois transactions travaillant sur des réels nommés A et B :
T1: { A+1 --> A; B+1 --> B }
T2: { A+2 --> A: B+2 --> B }
T3: { A*3 --> A: B*3 --> B }XXIV-42-1. Question 1▲
Donnez un exemple d'exécution simultanée des transactions T1 et T3 non sérialisable. Tracer le graphe de précédence associé.
XXIV-42-2. Question 2▲
Montrer que la commutativité de l'opération d'addition garantit la correction de toute exécution simultanée de T1 et T2.
XXIV-42-3. Question 3▲
La commutativité des opérations permet donc d'accepter des exécutions simultanées non a priori sérialisable. On se propose de munir chaque classe persistante d'un contrôleur de concurrence utilisant une matrice de commutativité des opérations et un vecteur d'opérations en cours par transaction.
Définir les primitives nécessaires à un tel contrôle de concurrence.
Préciser les algorithmes sous-jacents.
XXIV-43. TRANSACTIONS (chapitre XVI)▲
Soit le programme suivant écrit en C avec des requêtes SQL imbriquées (ESQLC de INGRES) :
#include <stdio.h>;
main (){
exec sql begin declare section;
char nombase [20];
char instr [150];
exec sql end declare section;
int i;
char rep;
printf ("Nom de la base : ");
scanf ("%s", nombase);
exec sql whenever sqlerror stop;
exec sql connect :nombase;
exec sql whenever sqlerror goto erreur;
for (i=1, rep = 'O'; rep = 'O'; i++){
printf ("\n\n Instruction %d : ", i);
scanf ("%s", instr);
exec sql execute immediate :instr;
exec sql commit;
suite :
printf ("\n\n Encore ?");
scanf ("%c", &rep);
}
printf ("\n\n Au revoir …");
exec sql disconnect;
return;
erreur :
exec sql whenever sqlerror continue;
Affic_Erreur (); procédure de gestion des erreurs
exec sql rollback;
exec sql whenever sqlerror goto erreur;
goto suite;
}XXIV-43-1. Question 1▲
Que fait ce programme ? Précisez le début et la fin de la (des) transaction(s).
XXIV-43-2. Question 2▲
Que se passe-t-il si on supprime l'instruction exec sql commit ?
XXIV-43-3. Question 3▲
Précisez les effets du rollback.
XXIV-43-4. Question 4▲
On lance plusieurs instances simultanées du programme précédent. Une transaction ne peut pas lire (et encore moins modifier) les données mises à jour par une transaction non validée. Pourquoi ?
Précisez les complications des procédures de reprise qu'impliquerait la levée de cette limitation, c'est-à-dire le non-respect de la propriété d'isolation des mises à jour.
XXIV-44. VALIDATION DE TRANSACTIONS (chapitre XVI)▲
Soit la base de données issue du banc d'essai TPC/A dont le schéma entité-association est représenté ci-dessous (en UML) :
L'objectif de l'étude est la résistance aux pannes dans un contexte centralisé puis réparti sur une telle base de données implémentée en relationnel.
XXIV-44-1. Question 1▲
Donnez le schéma relationnel de la base. Écrire le code de la transaction débit/crédit sous la forme de requêtes SQL.
XXIV-44-2. Question 2▲
Le système démarre après un point de reprise et exécute quatre instances de la transaction débit/crédit notées T1, T2, T3, T4. T1 crédite 1 000 F sur votre compte avec succès. T2 tente de créditer 2 000 F mais échoue, T3 crédite 3 000 F avec succès et T4 débite 4 000 F avec succès. Donnez le format du journal (images après et avant comme dans ARIES) après exécution de ces quatre transactions.
Ce journal est géré en mémoire. Quand est-il écrit sur disque ?
XXIV-44-3. Question 3▲
Le système tombe en panne après validation (commit) de T4. Que se passe-t-il lors de la procédure de reprise ?
XXIV-44-4. Question 4▲
Chaque agence bancaire possède un serveur gérant sa base de données. Écrire le code d'une transaction s'exécutant depuis un client C et effectuant le transfert de m francs depuis un compte d'une agence A sur le compte d'une agence B. Préciser les messages échangés entre client et serveurs dans le cas d'exécution avec succès d'une telle transaction, puis dans le cas où le site A ne répond plus lors de la première phase du commit.
XXIV-44-5. Question 5▲
Le site client lance la transaction de transfert qui est bien exécutée sur A et B. Malheureusement, le site client se bloque juste avant l'envoi de la demande de validation (COMMIT). Préciser l'état du système (messages échangés et journaux). Que se passe-t-il alors ?
Afin de sortir des situations de blocage, proposez une extension au protocole de validation à deux phases en ajoutant une phase et en introduisant un état intermédiaire basculant automatiquement en échec de la transaction après un délai d'attente.
XXIV-45. GESTION DES AUTORISATIONS (chapitre XVI)▲
Lorsqu'un usager crée une relation, tous les droits (lecture, insertion, suppression, modification) lui sont accordés sur cette relation. Cet usager a également le droit de transmettre ses droits à d'autres usagers à l'aide de la commande GRANT. Un usager ayant transmis des droits à un autre peut les lui retirer par la commande REVOKE.
XXIV-45-1. Question 1▲
Écrire la commande permettant de transmettre les droits de lecture et insertion sur la relation VINS à l'usager FANTOMAS, en lui garantissant le droit de transmettre ces droits.
Écrire la commande permettant de supprimer le droit précédent.
XXIV-45-2. Question 2▲
Afin de rendre plus souple l'attribution de droits, on introduit la notion de rôle. Précisez les commandes nécessaires à la gestion des rôles.
XXIV-45-3. Question 3▲
Les droits donnés aux usagers sont mémorisés dans une relation DROITS. Proposez un schéma pour la relation DROITS.
XXIV-45-4. Question 4▲
Décrivez en quelques lignes ou par un organigramme les principes des algorithmes d'accord de droit (GRANT), de suppression de droits (REVOKE) et de vérification d'un droit.
XXIV-46. NORMALISATION DE RELATIONS (chapitre XVII)▲
XXIV-46-1. PARTIE 1▲
Soit la relation R (A, B, C, D, E, F, G, H) avec la liste de dépendances fonctionnelles suivantes :
DF = { A→B, A→C, D→E, F→A, F→C, F→G, AD→C, AD→H }XXIV-46-1-1. Question 1▲
Proposez une couverture minimale DF- pour DF.
XXIV-46-1-2. Question 2▲
Dessiner le graphe des dépendances fonctionnelles.
XXIV-46-1-3. Question 3▲
Proposez une décomposition en troisième forme normale pour R.
XXIV-46-2. PARTIE 2▲
Soit la liste suivante de données élémentaires utilisées pour construire une base de données Commandes :
|
NUMCOM : numéro de commande |
Identifiant unique |
|
DATECOM : date de la commande |
|
|
NUMCLI : numéro de client |
Identifiant unique |
|
NOMCLI : nom du client |
Doubles possibles |
|
ADCLI : adresse client |
Doubles possibles |
|
NOMVEND : nom du vendeur |
Identifiant unique du vendeur qui passe la commande |
|
NUMPRO : numéro du produit |
Identifiant unique |
|
NOMPRO : nom du produit |
Doubles possibles |
|
PRIX : prix unitaire produit |
|
|
QTE : quantité commandée d'un produit |
|
|
MONTANT : montant pour la quantité commandée du produit |
|
|
TOTAL : prix total commande |
Montant total de la commande pour tous les produits commandés |
On suppose que l'on commence par former une unique relation Commandes avec les données précédentes pour attributs.
XXIV-46-2-1. Question 1▲
Proposez une liste de dépendances fonctionnelles entre ces attributs en respectant les hypothèses.
XXIV-46-2-2. Question 2▲
- Dessiner le graphe des dépendances fonctionnelles en utilisant des arcs en traits pleins pour la couverture minimale et des arcs en pointillé pour ceux qui peuvent se déduire par transitivité.
XXIV-46-2-3. Question 3▲
- Proposez une décomposition en troisième forme normale de la relation.
XXIV-47. INTÉGRITÉ DES BD OBJETS (chapitre XVII)▲
Soit le schéma de base de données objet suivant, donné dans un langage proche de C++ utilisant une définition de classe de grammaire CLASS <nom de classe> { [<type> <nom d'attribut>] …}, un type pouvant être simple (exemple : integer) ou complexe (exemple : SET<…>). Le constructeur de collection « SET » est utilisé pour préciser un ensemble d'objets du type indiqué entre crochets (exemple SET<PISTE*> désigne un ensemble de références à des pistes).
CLASS STATION { CHAR(20) NOMS, INTEGER ALTITUDE,
INTEGER HAUTEUR_NEIGE, SET<PISTE*> PISTES,
CHAR(10) REGION, CHAR(10) PAYS}
CLASS PISTE{ CHAR(12) NOMP, INTEGER LONG,
INTEGER DENIVELEE, SET<BOSSE*> DIFFICULTES}
CLASS BOSSE { INTEGER POSITION, CHAR CATEGORIE}On précise que :
- Il n'existe pas deux stations de même nom (NOMS).
- Une région appartient à un pays unique.
- ALTITUDE et HAUTEUR_NEIGE sont déterminés par le nom de station NOMS.
- Deux pistes de stations différentes peuvent avoir le même nom.
- Une piste dans une station possède une longueur et une dénivelée unique.
- La position d'une bosse la détermine de manière unique sur une piste donnée.
XXIV-47-1. Question 1▲
En considérant chaque classe, donnez le graphe des dépendances fonctionnelles entre attributs. Ajouter au graphe des arcs représentant les dépendances hiérarchiques de 1 vers N représentés par des arcs à tête multiple (du style -->>). Compléter ce graphe par les dépendances interclasses fonctionnelles ou hiérarchiques.
XXIV-47-2. Question 2▲
À partir du graphe précédent, déduire un schéma relationnel en 3e forme normale permettant de représenter la base de données objet initiale.
XXIV-47-3. Question 3▲
Préciser les contraintes d'unicité de clé du schéma relationnel. Spécifier ensuite les contraintes référentielles permettant d'imposer l'existence d'une station pour insérer une piste puis l'existence d'une piste pour insérer une bosse.
XXIV-47-4. Question 4▲
Proposez un langage de définition de contraintes permettant d'exprimer les mêmes contraintes dans le monde objet. Illustrez sur la base objet initiale.
XXIV-48. CONCEPTION COMPLÈTE D'UNE BD (chapitre XVII)▲
L'association (fictive) des Amateurs de Vins de Monde Entier (AVME) est une organisation à but non lucratif dont le but principal est de promouvoir l'entente entre les peuples par l'échange et la promotion des meilleurs vins du monde entier. Ses membres sont principalement des dégustateurs professionnels et des amateurs éclairés (qui bien sûr dégustent aussi). Ils désirent constituer une base de données recensant les vins, les dégustateurs (les membres) et tous les événements de dégustations. Ils ont demandé votre aide pour la conception du schéma relationnel, qui ne doit présenter ni anomalie ni redondance. La liste des données élémentaires qui doivent figurer dans la base est la suivante :
|
NUM_VIN |
Numéro d'un vin |
|
NUM_PRO |
Numéro d'un producteur de vin |
|
PRODUCTEUR |
Par exemple « Château Talbot » ou « Burgess Cellars » |
|
DESIGNATION |
Désignation additionnelle pour un vin, comme « Réserve » |
|
MILLESIME |
Année de production d'un vin |
|
CEPAGE |
Comme « Cabernet-Sauvignon » ou « Chardonnay » |
|
NOTE_MOY |
Note moyenne d'un millésime d'un vin |
|
PAYS |
Pays d'origine |
|
REGION |
Grande région de production, comme « Californie » aux USA, « Rioja » en Espagne ou « Bourgogne » en France |
|
CRU |
Petite région de production dont les vins ont un caractère marqué, comme « Napa Valley » ou « Haut-Médoc » |
|
QUALITE |
Qualité moyenne d'un cru pour un millésime |
|
NUM_MEM |
Numéro d'un membre |
|
NOM |
Nom d'un membre |
|
PRENOM |
Prénom d'un membre |
|
DATE |
Date d'un événement de dégustation |
|
LIEU |
Lieu d'un événement de dégustation |
|
NOTE |
Note attribuée à un millésime d'un vin par un dégustateur (membre) lors d'un événement dégustation |
|
RESP_REG |
Membre responsable d'une région viticole |
À titre d'explication et/ou de simplification, on notera que :
- les dégustations se font lors d'événements mettant en jeu de nombreux membres et de nombreux vins ;
- il n'y a jamais deux événements de dégustation à la même date ;
- un même vin est goûté de nombreuses fois lors d'un événement et reçoit une note pour chaque dégustateur qui l'a goûté, un dégustateur ne goûtant pas tous les vins ;
- deux régions de production n'ont jamais le même nom ;
- un même vin donne lieu à plusieurs millésimes (un par an) et tous les vins de la base sont des vins millésimés ;
- le producteur est le même pour tous les millésimes du même vin.
XXIV-48-1. Question 1▲
Donnez la liste des dépendances fonctionnelles non triviales entre données élémentaires sous la forme d'un graphe. S'assurer qu'il ne reste aucune dépendance fonctionnelle qui puisse se déduire des autres par transitivité (les enlever s'il en reste).
XXIV-48-2. Question 2▲
Proposez un schéma normalisé en 3FN pour la base DÉGUSTATION à partir de l'ensemble des dépendances fonctionnelles et à l'aide de l'algorithme vu en cours.
XXIV-48-3. Question 3▲
Exprimez en SQL les requêtes suivantes sur le schéma proposé :
- Quels sont les vins de 1991 de la région du Piémont (en Italie) qui ont reçu au moins une note supérieure à 17 lors de la dégustation du 14/05/1994 ?
- Quelle est la note moyenne décernée tous vins confondus par chaque membre (dégustateur) ?
- Quels sont les crus qui n'ont pas reçu de note inférieure à 15 pour le millésime 1989 ?
- Quels sont les dégustateurs qui ont participé à tous les événements ?
XXIV-48-4. Question 4▲
Donnez une expression des requêtes a) c) et d) en algèbre relationnelle (en utilisant de préférence la notation graphique vue en cours).
XXIV-48-5. Question 5▲
Proposez un schéma physique pour le schéma relationnel précédent. On suppose que l'on peut placer en séquentiel (avec index primaire non plaçant), par des index primaires plaçant de type arbre B+ ou par hachage classique. Choisir un mode de placement pour chaque relation en le justifiant.
XXIV-48-6. Question 6▲
Proposez les index secondaires les mieux à même d'accélérer la manipulation de la base. Indiquer les organisations d'index retenues dans chaque cas et donner les justifications des choix réalisés.