


XXIII. CONCLUSION ET PERSPECTIVES▲
XXIII-1. INTRODUCTION▲
Trois générations de systèmes de bases de données ont déjà vu le jour. La première génération des années 70 correspondait aux modèles hiérarchique et réseau. Elle était représentée par des produits tels TOTAL, IDS II, IMS et Socrate. La seconde génération des années 80 était basée sur le modèle relationnel et fut conduite par les produits Oracle, DB2, Ingres, Informix et Sybase. La 3e génération des années 90 a vu l'intégration de l'objet aux systèmes de 2e génération. Bien que des systèmes purs objets tels O2 ou Object Store aient montré le chemin, l'industrie a procédé par extension, si bien que d'un point de vue industriel Oracle, DB2, Informix et SQL Server restent les produits phares maintenant de 3e génération.
Les principes des systèmes de bases de données sont souvent venus de la recherche au cours de ces trente dernières années. L'enjeu aujourd'hui est le développement de la génération de SGBD de l'an 2000. Celle-ci devrait voir l'intégration efficace du décisionnel aux systèmes transactionnels, le support transparent de l'Internet et bien sûr la possibilité de recherche par le contenu des objets multimédias sur le Web vu comme une grande base de données. Tous ces travaux sont déjà bien engagés dans les laboratoires de recherche et chez les constructeurs de SGBD, notamment aux USA. Nous résumons ci-dessous quelques aspects des recherches en cours qui nous paraissent essentiels pour le futur.
XXIII-2. LES BD ET LE DÉCISIONNEL▲
La décennie 90 a vu le développement des entrepôts de données (Datawarehouse). Un entrepôt de données est un ensemble de données historisées variant dans le temps, organisé par sujets, agrégé dans une base de données unique, géré dans un environnement de stockage particulier, aidant à la prise de décision dans l'entreprise. Trois fonctions essentielles sont prises en compte par ces nouveaux systèmes décisionnels : la collecte de données à partir de bases existantes et le chargement de l'entrepôt, la gestion et l'organisation des données dans l'entrepôt, l'analyse de données pour la prise de décision en interaction avec les analystes.
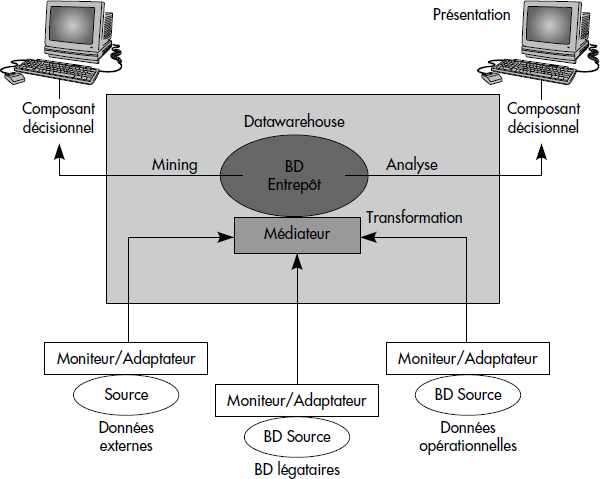
La figure XVIII.1 illustre les composants d'un entrepôt de données. Le moniteur-adapteur est chargé de la prise en compte des mises à jour des sources de données locales, de la préparation de tables différentielles (les deltas) pour envois à l'entrepôt et du transfert des deltas périodiquement vers le médiateur. Ce dernier assure la fusion des sources et la mise en forme des données pour la base de l'entrepôt. Autour du datawarehouse, les outils OLAP (On Line Analysis Processing) permettent l'analyse des données historisées. Les outils de data mining permettent l'extraction de règles et de modèles à partir des données.
XXIII-2-1. L'ANALYSE INTERACTIVE MULTIDIMENSIONNELLE (OLAP)▲
Le développement de l'analyse interactive de données (OLAP) a été basé sur l'utilisation de cubes multidimensionnels [Gray96]. Un cube permet la visualisation et l'analyse d'une mesure selon trois axes. Par exemple, un chiffre d'affaires sera représenté dans un espace 3-D, en fonction du temps, des produits vendus et de la géographie. Ce cube de données (datacube) peut être manipulé par des opérations basées sur une algèbre des cubes de données composée d'opérateurs de tranches, extensions et agrégats (slice, dice, rollup, drilldown).
Les problèmes de performances dans le cadre de larges bases de données historisées sont nombreux : Que concrétiser dans l'entrepôt ? Comment gérer des vues redondantes pour faciliter le calcul des cubes ? Comment passer du relationnel au multidimensionnel ? Et plus généralement, comment concevoir la base de l'entrepôt ? Comment choisir les résumés stockés, les vues concrétisées, maintenir les métadonnées [Mumick97] ?
XXIII-2-2. LA FOUILLE DE DONNÉES (DATA MINING)▲
Au-delà de l'analyse interactive multidimensionnelle, les techniques de fouille de données (Data mining) se sont répandues. Il s'agit d'un ensemble de techniques d'exploration de larges bases de données afin d'en tirer les liens sémantiques significatifs et plus généralement des règles et des modèles pour la compréhension et l'aide à la décision. Les domaines d'applications sont nombreux, par exemple l'analyse de risque, le marketing direct, la grande distribution, la gestion de stocks, la maintenance, le contrôle de qualité, le médical, l'analyse financière. L'approche consiste souvent à induire des règles avec des coefficients de vraisemblance à partir de large ensemble de données. Les techniques de base sont issues de l'IA et de l'analyse de données (analyse statistique, modèles fonctionnels, réseaux de neurones, recherche de règles associatives, classification, segmentation, etc.). La problématique BD est le passage à l 'échelle, c'est-à-dire être capable de traiter quelques gigaoctets de faits ! Par exemple, des index spécialisés (bitmap) et des échantillonnages contrôlés ont été proposés. Les techniques de découvertes de règles associatives ont été particulièrement développées [voir par exemple Agrawal93, Gardarin98].
XXIII-3. BD ET WEB▲
Le Web s'est développé comme un hypertexte sur le réseau Internet, pour permettre facilement l'accès à des fichiers chaînés. Rapidement, le besoin de couplage avec les bases de données est apparu. Pourquoi coupler ? Trois raisons au moins motivent ce besoin : l'introduction du client-serveur à présentation universelle (architectures 3-tiers), la génération de sites Web dynamiques composés à partir de templates HTML et de données extraites de bases, et le commerce électronique, qui nécessite la gestion de catalogues et de transactions en bases de données.
Il existe déjà de nombreuses solutions industrielles, plus ou moins issues de la recherche, telles Oracle Web, Web SQL de Sybase, LiveWire de Netscape, Visual Interdev de Microsoft, O2 Web, etc. Ces outils réalisent une intégration faible de deux modèles de données (le relationnel-objet et le modèle semi-structuré abstrait de HTML). Ils sont insuffisants, car ils ne permettent guère la transcription automatique de résultats de requêtes en HTML et vice-versa.
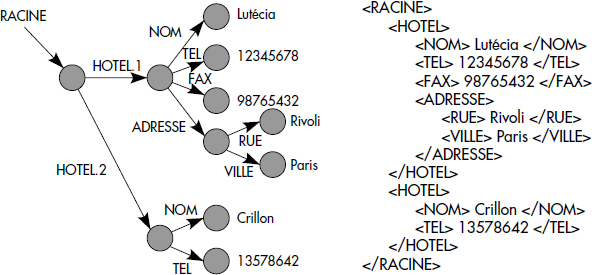
De nombreux projets de recherche (par exemple, Tsimmis à Stanford [Abiteboul97], Strudel à ATT [Fernandez97], MiroWeb au PriSM en collaboration avec Osis et l'Inria) tendent à permettre le stockage direct d'hypermédia dans la base. XML paraît le standard adapté pour les bases de données semi-structurées. Les principaux projets proposent des modèles de représentation de documents XML et des langages d'interrogation associés. Les bases de données semi-structurées [Abiteboul96, Buneman97] modélisent les données par un graphe étiqueté, chaque nœud feuille pouvant correspondre à un objet externe, structuré ou non. Les étiquettes correspondent aux tags XML. La figure XVIII.2 illustre un document semi-structuré représenté sous la forme d'un graphe et en XML.
Le semi-structuré paraît bien adapté au Web. Il permet en effet la prise en compte de documents HTML/XML et facilite l'interrogation et la recomposition dynamique de partie de documents multimédias. Il autorise aussi la navigation intelligente dans une base de documents. Un document distribué est représenté par un réseau sémantique d'objets liés. Les liens correspondent à des arcs de composition ou d'association. La grammaire des documents (DTD) peut être maintenue comme une nouvelle sorte de contrainte d'intégrité. La question d'intégrer le semi-structuré aux SGBD existants reste posée. Elle nécessite en particulier la capacité à découvrir des structures répétitives dans les documents, afin de les représenter sous forme d'extensions de types. Les langages SQL ou OQL doivent aussi être étendus pour manipuler les graphes d'objets semi-structurés, par exemple avec des parcours de chemins et des expressions régulières [Abiteboul97, Arocena98, Consens93, Fernandez97, Konopnicki95, Mendelzon96].
La réalisation d'adaptateurs capables de générer une vue semi-structurée de sources de données structurées ou non est aussi un problème d'actualité. Il faut non seulement comprendre la sémantique des sources afin de découvrir un peu de structure, mais aussi assurer le passage du structuré au semi-structuré. Des vues partielles de sources sous forme de graphes étiquetés doivent être générées sur demande à partir de requêtes.
L'optimisation de requêtes mixant des données structurées et semi-structurées pose aussi des problèmes nouveaux. Il faudrait pouvoir disposer d'un modèle de coût pour données semi-structurées. La gestion de documents distribués (sur Intranet ou Internet) nécessite aussi des techniques d'optimisation originale pouvant allier les approches push et pull.
XXIII-4. BD MULTIMÉDIA▲
Le multimédia est à la mode [Subrahmanian96]. Il est reconnu qu'une BD multimédia doit posséder cinq caractéristiques :
- Gérer des types de données multimédias incluant texte libre, géométrie, image, son, vidéo ;
- Offrir les fonctionnalités des bases de données, c'est-à-dire l'existence d'un langage d'interrogation non procédural permettant les recherches par le contenu, la persistance, la concurrence et la fiabilité ;
- Assurer la gestion de larges volumes de données, pouvant atteindre les péta-bases (10**15) ;
- Supporter des structures de stockage efficaces comme les Quadtree, les Rtree et leurs variantes, pour permettre la recherche rapide par le contenu ;
- Être capable de récupérer des informations à partir de sources hétérogènes.
L'interrogation d'objets multimédias passe par la recherche classique dans une BD structurée à partir d'attributs décrivant les objets (exact-match retrieval), mais surtout par la recherche basée sur le contenu des objets. Une requête typique est la recherche des k objets les plus similaires à un objet donné. Là, il n'y a pas de garantie sur la correction et la précision des résultats. On récupère un ensemble de résultats classé par ordre de pertinence et interrogeable à nouveau (raffinement). Dans cet esprit, une extension de SQL3 avec des types de données abstraits spécifiques au multimédia est en cours de conception par un sous-groupe de l'ISO : SQL multimédia (SQL/MM). Il s'agit d'un projet international de standardisation dont l'objectif est de développer une librairie de types SQL pour les applications multimédias. SQL/MM est composé de diverses parties amenées à évoluer : Full text, Graphic still, Animation, Image still, Full motion video, Audio, Spatial 2D et 3D, Music. Tous ces types de données devraient être standardisés, en conjonction avec d'autres efforts (MPEG 7 par exemple).
Les thèmes de recherche liés au multimédia sont nombreux et sortent souvent du strict domaine des bases de données. Il s'agit en particulier de l'indexation automatique [Salton88], de l'extraction de caractéristiques (features), de l'évaluation de distances combinées entre objets, de la gestion de proximité sémantique, du développement de structures de stockage efficaces. L'optimisation de requêtes, les modèles de coûts, la formulation et l'évaluation de requêtes mixtes, l'intégration aux SGBD existants, la distribution et la recherche sur Internet/Intranet devraient aussi contribuer à la constitution de musées virtuels interrogeables par le contenu sur les grands réseaux.
XXIII-5. CONCLUSION▲
Les bases de données ont connu une évolution douce vers l'objet, le standard étant aujourd'hui le relationnel-objet et SQL3. Les domaines les plus actifs sont le décisionnel, l'intégration avec le Web et le multimédia. Nous développons ces thèmes dans un ouvrage complémentaire. Les bases de données mobiles ne sont pas non plus à négliger et la conception, notamment d'entrepôt de données et de BD actives, reste un problème ouvert. Il ne faut pas non plus négliger les thèmes de recherche traditionnels où il y a encore beaucoup à faire (méthodes d'accès, concurrence, réparti, intégrité et vues, parallélisme).
Un sondage effectué récemment auprès de 20 chercheurs reconnus (comité de programme de CIKM) sur leurs domaines d'intérêt a donné les résultats indiqués figure XVIII.3. La note est un poids entre 0 et 20 (intérêt ou non).
Si l'on analyse les thèmes des articles des derniers VLDB et SIGMOD, on obtient des résultats sensiblement différents comme indiqué figure XVIII.4. Tout ceci montre à la fois la multiplicité, la diversité et l'ouverture de la recherche en bases de données. Les enjeux économiques sont très grands, ce qui explique la croissance du nombre de chercheurs (400 articles soumis au dernier VLDB, 220 à CIKM).
|
Semi-structured and Web Database |
20 |
|
Heterogeneous and Distributed System |
16 |
|
Query Languages and Query Processing |
16 |
|
Application |
15 |
|
DataWarehousing and Mining |
14 |
|
Multimedia Databases |
11 |
|
Database Design |
10 |
|
Active & Rule Databases |
9 |
|
Object Storage Methods |
8 |
|
User and Application Interfaces |
8 |
|
Imprecise and Uncertain Information |
6 |
|
Parallel database systems |
5 |
|
Transaction and Reliability |
4 |
|
Tuning, Benchmarking and Performance |
3 |
|
Privacy and Security Issues |
3 |
|
Multimedia Databases |
19 |
|
DataWarehousing and Mining |
18 |
|
Query Languages and Query Processing |
9 |
|
Semi-structured and Web DB |
7 |
|
Heterogeneous an Distributed Systems |
7 |
|
Object Storage Methods |
7 |
|
Transaction and Reliability |
7 |
|
Active & Rule Databases |
5 |
|
Tuning, Benchmarking and Performance |
4 |
|
Application |
3 |
|
Database Design |
3 |
|
User and Application Interfaces |
2 |
|
Parallel database systems |
2 |
|
Imprecise and Uncertain Information |
1 |
|
Privacy and Security Issues |
1 |
Pour terminer, nous voudrions souligner la vertu des prototypes et des applications en bases de données. La réalisation de systèmes plus ou moins exploratoires (Socrate, Syntex, Sabre, O2) a permis par le passé de constituer des équipes à masse critique de pointe. Elle permet aussi d'acquérir des connaissances, de les maintenir et de les passer à de nouveaux chercheurs au sein d'un système. Il ne faudrait pas que la réduction et la dispersion des crédits conduisent à abandonner les grands projets au profit de publications souvent secondaires.
La réalisation d'applications à l'aide de prototypes avancés permet de cerner les véritables besoins et de découvrir des sujets neufs. De grandes expériences couplées au réseau (Intranet ou Internet) sont déjà en cours par exemple au Musée du Louvre et à Bibliothèque Nationale. Une meilleure participation de la recherche dans ces projets est souhaitable.
XXIII-6. BIBLIOGRAPHIE▲
[Abiteboul97] Abiteboul S., « Querying semi-structured data », Proc. Of the International Conference on Database Theory (ICDT), Jan. 1997.
- Une mise en perspective théorique des bases de données semi-structurées.
[Abiteboul97] Abiteboul S., Quass D., McHugh J., Widom J., Weiner J., « The Lorel Query Language for Semi-structured Data », Journal of Digital Libraries, vol. 1, n° 1, p. 68-88, April 1997.
- Cet article présente le langage LOREL, extension de OQL pour les données semi-structurées.
[Agrawal93] Agrawal R., Imielinski T., Swami A. N., « Mining Association Rules between Sets of Items in Large Databases », Proc. of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, D.C., 1993, p. 207-216.
- Le premier article sur les règles associatives. Il propose la méthode Apriori pour extraire les règles associatives de grandes bases de données.
[Arocena98] Arocena G., Mendelzon A., « WebOQL : Restructuring documents, databases and Webs », in Proc. IEE ICDE 98, Orlando, Florida, Feb. 1998.
- Cet article propose un langage d'interrogation pour le Web construit à partir d'OQL.
[Buneman97] Buneman P., « Semi-structured data », Proc. ACM PODS'97, Tucson, Arizona, USA, p. 117-121, 1997.
- Cet article présente un tutoriel sur les données semi-structurées. En particulier le langage UnQL et les premières techniques d'optimisation, en particulier pour les expressions régulières, sont décrits.
[Consens93] Consens M., Mendelzon A., « Hy+ : A hygraph-based query and Vizualisation System », SIGMOD Record, vol. 22, n° 2, p. 511-516, 1993.
- Un des premiers langages d'interrogation pour hypertexte.
[Gardarin98] Gardarin G., Pucheral P., Wu F., « Bitmap Based Algorithms For Mining Association Rules », rapport PriSM, Proc. BDA'98, Tunis, octobre 1998.
- Un algorithme de découverte de règles associatives basé sur des index spécialisés, de type bitmap.
[Gray96] Gray J., Bosworth A., Layman A., Pirahesh H., « Data Cube : A relational aggregation operator generalizing group-by, cross-tab, and sub-total », Proc. of the 12th IEEE Data Engineering Conf., p. 152-159, New-Orleans, Feb. 1996.
- Un des premiers articles formalisant le datacube et l'introduisant comme une construction en SQL.
[Konopnicki95] Konopnicki D., Shmueli O., « W3QS : A Query System for the World Wide Web », Proc. Of the 21st VLDB, Zurich, Switzerland, 1995.
- Un autre langage d'interrogation pour le Web.
[Mendelzon96] Mendelzon, Mihaila G., Milo T., « Querying the World-Wide Web », Proc. Of 1st Int. Conf. On Parallel and Distributed Information Systems, p. 80-91, Dec. 1996.
- Une formalisation de langages d'interrogation pour le Web.
[Mumick97] Mumick S.I., Quass D., Mumick B.S., « Maintenance of Data Cubes and Summary Tables in a Warehouse », in Proc. of ACM SIGMOD'97, Sigmod Record n° 26, vol. 26, n° 2, p. 100-111, 1997.
- Cet article propose une méthode pour maintenir des vues avec agrégats dans un entrepôt de données. Les mises à jour sont envoyées périodiquement sous forme de tables différentielles ou deltas. Tout d'abord, un algorithme efficace de propagation des mises à jour sur une vue est proposé. Puis, il est montré comment un ensemble de vues support de cubes de données peut être maintenu efficacement.
[Salton88] Salton G., Buckley C., « Term-weighting approaches in automatic text retrieval », Information Processing & Management, vol. 24, p. 513-523, 1988.
- Cet article présente une méthode basée sur des matrices de fréquence de termes pour interroger les bases de données textuelles.
[Subrahmanian96] Subrahmanian V.S., Jajodia S. editors, Multimedia Database Systems, Springer-Verlag, 323 pages, Berlin, 1996.
- Cet excellent livre sur le multimédia donne une vue d'ensemble des techniques proposées pour les BD images, textes, vidéo et audio. Il fait aussi un tour des techniques de stockage et de publications de documents multimédias.