IX. Organisation physique▲
IX-A. Une organisation physique simple▲
Soit la BD relationnelle :
- livre(titre, auteur)
- personne(nom, prénom, âge)
La relation livre est stockée dans un fichier livre.txt dont chaque enregistrement représente un doublet de la relation livre et a deux champs : les valeurs des attributs titre et auteur de ce triplet.
La relation personne est stockée dans un fichier personne.txt dont chaque enregistrement représente un triplet de la relation personne et a trois champs : les valeurs des attributs nom, prénom et âge de ce triplet.
Deux métarelations décrivant les relations de la BD et leurs attributs :
- relation(nom, nb_att)
- attribut(nom_table, nom, type, rang)
sont elles-mêmes stockées dans les fichiers relation.txt et attribut.txt.
IX-A-1. La base de données▲
|
livre |
|
|---|---|
|
titre |
auteur |
|
BD et SGBD |
Dupont |
|
XML |
Durand |
|
personne |
||
|---|---|---|
|
nom |
prénom |
âge |
|
Dupont |
Jean |
18 |
|
Durand |
Pierre |
20 |
IX-A-2. Les fichiers▲
fichier table.txt
- personne|3
- livre|3
fichier attribut.txt
- livre|titre|texte|1
- livre|auteur|texte|2
- personne|nom|texte|1
- personne|texte|2
- personne| age|entier|3
fichier livre.txt
- BD et SGBD|Dupont
- XML|Durand
fichier personne.txt
- Dupont|Jean|18
- Durand|Pierre|20
IX-A-3. Évaluation d'une requête▲
La requête :
2.
3.
4.
SELECT livre.titre
FROM livre, personne
WHERE livre.auteur = personne.nom AND
personne.age = 30;
L'algorithme :
pour chaque enregistrement l du fichier livre.txt
pour chaque enregistrement p du fichier personne.txt
si l.3 = p.1 et p.3 = 30 alors afficher l.2;
IX-A-4. Les limites de cette organisation▲
La modification d'un n-uplet impose de réécrire le fichier.
Le temps d'exécution d'une requête peut être coûteux, car les relations sont parcourues séquentiellement.
Pas de mémorisation en mémoire centrale des n-uplets fréquemment accédés.
Pas de contrôle de concurrence.
Pas de sécurité en cas de panne.
IX-B. Objectifs d'une bonne organisation physique▲
Une BD relationnelle est constituée d'un ensemble de relations qui ont chacune une extension qui est un ensemble de n-uplets.
Physiquement, ces n-uplets sont stockés dans un ou plusieurs fichiers qui peuvent être répartis sur un ou plusieurs sites (dans le cas de BD distribuées).
Le format de stockage choisi doit permettre :
- une utilisation optimale de la mémoire ;
- un accès rapide et des mises à jour peu coûteuses.
Afin d'accéder le plus rapidement possible à un ensemble de n-uplets vérifiant certaines conditions, une BD relationnelle doit être munie d'index qui permettent d'associer chaque valeur d'un constituant à l'ensemble des n-uplets qui possèdent cette valeur pour ce constituant.
IX-B-1. Hiérarchie de mémoire▲
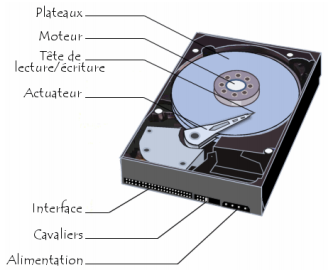
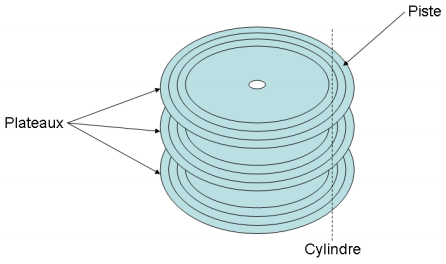
IX-B-1-a. Disques durs▲
IX-B-2. Adresse physique d'un n-uplet▲
Les n-uplets d'une BD relationnelle sont rangés dans des pages.
Une page est stockée dans un bloc d'un disque.
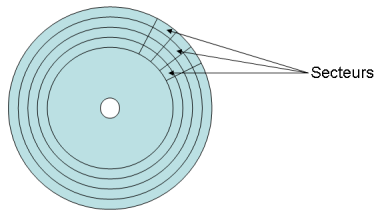
En général, un bloc est stocké sur plusieurs secteurs consécutifs du disque.
Dans le cas général où une BD est répartie sur plusieurs sites et est stockée sur plusieurs disques sur un site, l'adresse physique d'un nuplet est composée de :
- l'identificateur du site ;
- l'identificateur du disque ;
- le numéro de la tête de lecture (surface) ;
- le numéro de la piste ;
- le numéro du 1er secteur du bloc ;
- le début du n-uplet dans le bloc.
IX-B-3. Identification d'un n-uplet▲
Il est nécessaire d'identifier chaque n-uplet afin :
- de les distinguer des autres n-uplets ;
- de pouvoir y accéder à partir des index.
Deux modes d'identification peuvent être utilisés :
- par son adresse physique ;
- par son adresse logique ;
- par combinaison des deux.
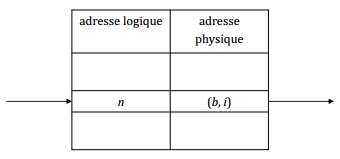
IX-B-3-a. Adresse logique d'un n-uplet ▲
Les n-uplets sont numérotés consécutivement à partir de 0 ou 1.
Une table de correspondance permet de faire le lien entre l'adresse logique d'un n-uplet et son adresse physique.
IX-B-3-b. Combinaison adressage physique/adressage logique (1)▲
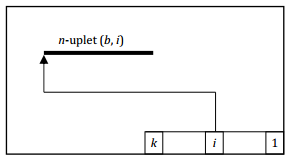
L'adressage logique est réalisé à l'intérieur de chaque page.
Une page est découpée en deux zones :
- la zone des n-uplets : les n-uplets y sont implantés dans un ordre quelconque ;
- un répertoire qui est implanté à partir de la fin de la page. La ie case de ce répertoire indique le déplacement dans la page du n-uplet de rang i.
IX-C. Évolution de la taille des n-uplets▲
Si la longueur d'un n-uplet augmente de k octets, deux cas sont possibles :
- s'il reste suffisamment de place dans la page, on décale les n-uplets qui le suivent de k octets vers la droite, puis on change leur adresse logique dans le répertoire ;
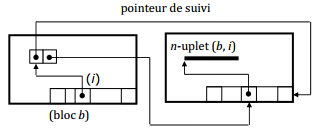
- sinon, on change le n-uplet de page et on met en place un pointeur de suivi.
Si la longueur d'un n-uplet diminue de k octets, on décale les n-uplets qui le suivent de k octets vers la gauche, puis on change leur adresse logique dans le répertoire.
IX-C-1. Pointeur de suivi▲
IX-D. Représentation des valeurs d'attributs▲
Elles peuvent être représentées :
- sous leur forme externe ;
- sous la forme sous laquelle elles sont utilisées par les programmes d'application.
IX-E. Représentation des n-uplets▲
Le choix d'une représentation doit prendre en compte les critères suivants :
- possibilité de représenter des attributs de longueur variable ;
- évolutivité des schémas de relation par ajout ou suppression d'attributs ;
- rapidité d'accès aux valeurs d'attributs.
n-uplets courts (taille < à celle d'une page)
-
format fixe
- les valeurs d'attributs sont enregistrées dans des champs de longueur fixe,
-
format variable
-
les valeurs d'attributs sont stockées les unes derrière les autres :
- soit précédées de leur longueur,
- soit précédées de leur nom.
-
n-uplets longs (taille > à celle d'une page)
- les valeurs longues (images, vidéo…) sont stockées à part dans une suite consécutive de blocs,
- le n-uplet est ensuite représenté comme un n-uplet court en remplaçant chaque valeur longue par un pointeur vers le 1er bloc la contenant.
Soit la table :
2.
3.
4.
CREATE TABLE personne (
nom CHAR(15),
prenom CHAR(10),
age SMALLINT);
Format fixe
Dupont_________Jean______30 (27 octets)Format variable
6Dupont4Jean230 (longueur)
nom#Dupont#prénom#Jean#age#18 (nom)IX-F. Échange disque/mémoire centrale▲
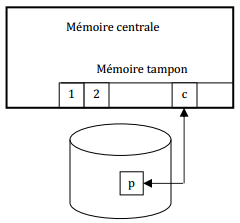
Les échanges de données entre disque et mémoire centrale se font au travers d'une zone particulière de la mémoire appelée mémoire tampon (buffer).
Les objectifs sont :
- de rendre les pages et les n-uplets qu'elles contiennent accessibles en mémoire centrale ;
- de coordonner l'écriture des pages sur le disque en coopération avec le gestionnaire de transactions ;
- de minimiser le nombre d'accès disques.
IX-F-1. Structure de la mémoire tampon▲
La mémoire tampon est formée d'une suite de cases dont chacune peut contenir une page. En mémoire centrale une page est donc repérée par le numéro de la case du tampon dans laquelle elle est rangée.
IX-G. Recherche d'une page▲
L'opération de recherche d'une page :
- a pour argument l'adresse p de la page cherchée ;
- retourne l'adresse c de la case du tampon dans laquelle cette page est rangée.
L'algorithme est le suivant :
- si la page p est dans la case c du tampon, retourner c. On économise un accès disque ;
- si la page p n'est pas dans le tampon, il faut la lire sur le disque. On teste s'il existe une case libre pour la recevoir. Si oui, soit c cette case ;
- sinon, il faut libérer une case et donc renvoyer une page du tampon sur le disque. Plusieurs stratégies sont possibles ;
- si la page à rejeter a été modifiée pendant son séjour en mémoire centrale, il faut la réécrire sur le disque. Ce travail est pris en compte par le gestionnaire de transactions ;
- transférer la page p du disque dans la case c et retourner c.
IX-H. Stratégies de remplacement de page▲
FIFO (First-In First-Out)
- On renvoie sur disque la page qui n'a pas été utilisée depuis le plus longtemps. Cette stratégie repose sur l'hypothèse que cette page a moins de chances d'être réutilisée que les autres.
LIFO (Last-In First-Out)
- On renvoie sur disque la page qui a été utilisée le plus récemment. L'intérêt de cette stratégie est sa simplicité, car n'y a pas besoin de mémoriser les dates auxquelles les pages ont été chargées dans le tampon.
Sous contrôle du SGBD
- Le SGBD peut punaiser (« to pin ») des pages dans la mémoire tampon, afin qu'elles ne soient pas renvoyées sur disque, car il sait qu'elles vont être réutilisées.
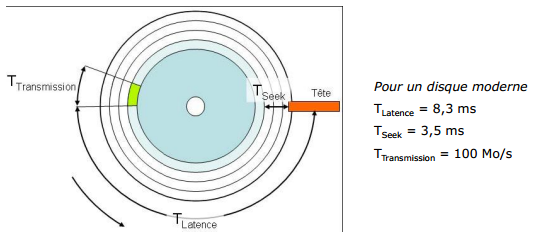
IX-I. Temps d'accès à un n-uplet▲
L'accès à un n-uplet consiste donc à :
- Rechercher sur le disque la page qui le contient ;
- Le rechercher dans cette page.
Le temps d'accès à un n-uplet est donc égal à :
- Trecherche dans page + Ttransfert page
Trecherche dans page est négligeable par rapport à Ttransfert page.
Le temps d'accès à une page dépend de sa localisation (mémoire tampon ou disque).
En conclusion, il y a intérêt :
- à regrouper dans une même page les n-uplets traités consécutivement ;
- à traiter consécutivement les n-uplets d'une même page.
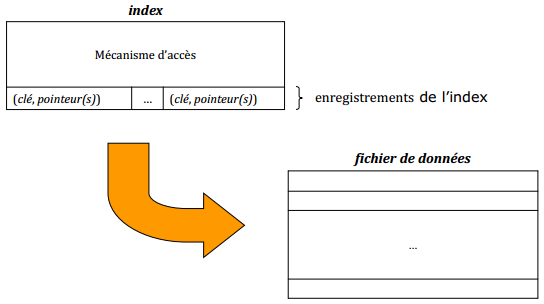
IX-J. Index ▲
Un index est un fichier construit pour accéder de façon sélective, et donc rapide, aux enregistrements d'un fichier de données D, dont la valeur c d'un champ ou d'une liste de champs est donnée :
- c est appelée une clé de recherche.
Un index est composé de deux parties :
-
un fichier d'enregistrements à deux champs :
- une clé de recherche c,
- un pointeur ou une liste de pointeurs vers des enregistrements de D ;
- un mécanisme d'accès à un enregistrement de l'index à partir de la clé de recherche.
IX-J-1. Structure d'un index ▲
IX-J-2. Index primaire/index secondaire▲
Un index est dit :
-
primaire si la clé de recherche est une clé d'un enregistrement du fichier de données :
- en ce cas, un enregistrement de l'index pointe vers un seul enregistrement du fichier de données ;
-
secondaire sinon :
- en ce cas, un enregistrement de l'index peut pointer vers plusieurs enregistrements du fichier de données.
IX-J-3. Index dense/index creux ▲
Un index est dit :
- dense si chaque clé de recherche dans le fichier de données apparaît dans l'index ;
- creux si seulement certaines clés du fichier de données apparaissent dans l'index (en général, une clé par bloc du fichier de données).
Un index dense est dit :
- groupant, si ses enregistrements et ceux du fichier de données sont triés selon la clé de recherche ;
- non groupant, sinon.
Un index secondaire est toujours dense.
IX-J-4. Index dans les BD relationnelles▲
Dans une BD relationnelle, les index sont construits sur une relation, par la commande SQL :
CREATE INDEX nom ON relation(liste d'attributs)Pour une relation R, on distingue :
-
l'index primaire construit sur la clé primaire de R :
- il donne accès au n-uplet dont la clé primaire est donnée, ou à son identificateur ;
-
les index secondaires construits sur un attribut ou une liste d'attributs de R :
- ils donnent accès aux identificateurs des n-uplets dont la valeur pour ce constituant est donnée.
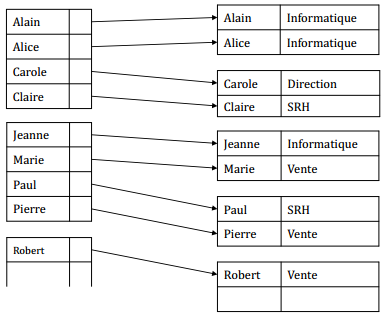
IX-K. Exemple : la table▲
|
employé |
|
|---|---|
|
nom |
département |
|
Alain |
Informatique |
|
Pierre |
Vente |
|
Marie |
Vente |
|
Jeanne |
Informatique |
|
Carole |
Direction |
|
Paul |
SRH |
|
Alice |
Informatique |
|
Claire |
SRH |
|
Robert |
Vente |
IX-K-1. Index primaire dense▲
IX-K-2. Index primaire creux▲
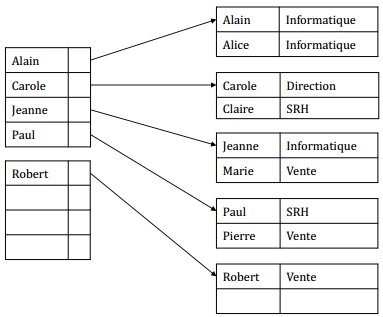
IX-K-3. Index secondaire groupant▲
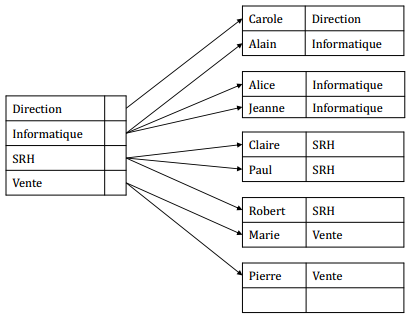
IX-K-4. Index secondaire non groupant▲
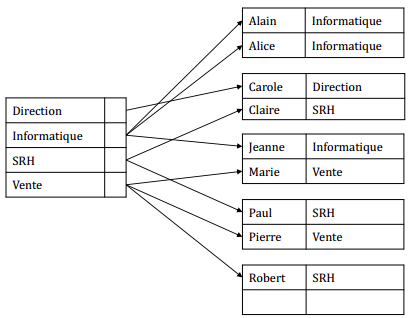
IX-L. Mécanisme d'accès aux enregistrements d'un index▲
Organisation arborescente :
- séquentiel-indexé,
- arbres B+
Accès par hachage :
- statique
- dynamique
IX-L-1. Exemple : la table sur laquelle sera construit l'index▲
Chaque mécanisme d'accès sera illustré par la construction de l'index primaire, que nous appellerons dico, de la relation suivante :
|
dictionnaire |
|
|---|---|
|
mot |
définition |
|
mélodie |
Suite de sons formant un air… |
|
école |
Établissement où se donne un enseignement collectif… |
|
nez |
Partie saillante du visage… |
|
bateau |
Nom des embarcations, des navires… |
|
kayak |
Embarcation étanche et légère… |
|
zébu |
Bœuf à longues cornes et à bosse sur le garrot… |
|
dessin |
Représentation sur une surface de la forme d'un objet… |
|
corde |
Assemblage de fils tressés ou tordus ensemble… |
|
Terre |
Planète habitée par l'homme… |
IX-M. Arbre B+▲
Les arbres B ont été introduits par Bayer et McCreight en 1972 et ont fait l'objet de nombreux développements par la suite.
Nous décrivons une variante des arbres B : les arbres B+, qui sont très largement utilisés pour construire des index de BD.
IX-M-1. Structure d'un arbre B+▲
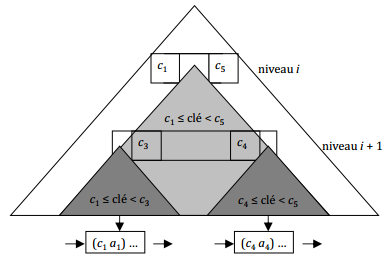
IX-M-2. Organisation d'un arbre B+▲
Un arbre B+ d'ordre m (entier impair ≥ 3) est un arbre équilibré dont chaque nœud est enregistré dans une page stockée sur disque.
Une feuille contient une séquence d'enregistrements :
- (c1 a1) … (ck ak) p
où :
- ci est une clé et ai est l'information associée à cette clé ;
- p est un pointeur vers la feuille suivante,
triée par ordre croissant de clé.
Une feuille est au moins à moitié remplie :
- (m + 1) / 2 ≤ k ≤ m
sauf si elle est l'unique nœud de l'index.
Les feuilles sont chaînées entre elles dans l'ordre de leur première clé à l'aide du pointeur p.
Un nœud non terminal contient une séquence d'enregistrements :
- (p1) … (ck pk)
où :
- ci est une clé ;
- pi (1 ≤ i ≤ m - 1) est un pointeur vers la racine du sous-arbre dont les feuilles contiennent les enregistrements dont la clé est égale ou supérieure à ci et inférieure à ci + 1 ;
- pm est un pointeur vers la racine du sous-arbre dont les feuilles contiennent les enregistrements dont la clé est égale ou supérieure à cm,
triée par ordre croissant de clé.
Un nœud est au moins à moitié rempli
- (m + 1) / 2 ≤ k ≤ m
sauf s'il est la racine, auquel cas son contenu peut se réduire à :
- (p1) … (c2 p2).
IX-M-3. L'index dico en arbre B+▲
L'arbre B+ est d'ordre m = 3.
Seules les clés des enregistrements sont représentées.
IX-M-4. Recherche d'un enregistrement▲
(Il s'agit de rechercher l'enregistrement dont la clé c est donnée ou, s'il n'existe pas, le nœud qui devrait le contenir.)
début
Le nœud courant est la racine de l'arbre B+.
tant que le nœud courant est un nœud non terminal
de contenu (p1) (c2, p2)… (cn, pn) répéter
si c < c2 alors
Accéder au nœud d'adresse p1 qui devient le nœud courant.
sinon
Rechercher séquentiellement le dernier ci inférieur
ou égal à c et accéder au nœud d'adresse pi qui devient le
nœud courant.
fsi
fin
Rechercher l'enregistrement de clé c dans le nœud courant
(une feuille).
fin
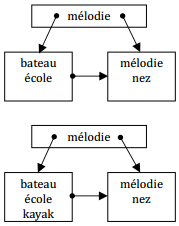
IX-M-5. Recherche de nez dans l'index dico▲
IX-M-6. Insertion▲
(Il s'agit d'insérer l'enregistrement de clé c et d'information associée a.)
début
Rechercher l'enregistrement de clé c.
si il existe alors
L'insertion est terminée.
sinon
Le nœud courant est celui sur lequel s'est arrêtée la recherche
et l'enregistrement à insérer est (c, a).
répéter
Soit n le nœud courant, p son adresse et s le contenu de n.
Insérer l'enregistrement à insérer dans s en respectant l'ordre des clés.
si longueur(s) ≤ m alors
Enregistrer s dans n.
L'insertion est terminée.
sinon
fission du nœud courant
fsi
jusqu'à ce que l'insertion soit terminée
fsi
fin
(La longueur d'une séquence est le nombre d'enregistrements qui la composent.)
IX-M-7. Fission d'un nœud▲
(Il s'agit de répartir sur deux nœuds le nouveau contenu s du nœud n d'adresse p)
début
Créer un nouveau nœud n' d'adresse p'.
Découper s en deux séquences s1 et s2 de longueur égale :
c'est possible, car la longueur de s est m + 1 qui est un nombre pair.
Soit c21 la première clé de s2.
Enregistrer s1 dans n.
Enregistrer s2 dans n' après avoir supprimé sa première clé,
si n' est un nœud non terminal.
si n est une feuille alors
Chaîner n' à n.
fsi
si n est la racine alors
Créer un nouveau nœud de contenu (p) (c21 p').
L'insertion est terminée (la hauteur de l'index a augmenté de 1).
sinon
Le père de n devient le nœud courant
et (c21 p') devient l'enregistrement à insérer.
fsi
fin
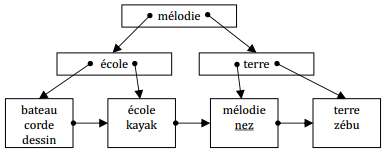
IX-M-8. Construction de l'index dico▲
Insertions successives des enregistrements : mélodie, école, nez.

Insertions successives des enregistrements : bateau, kayak.
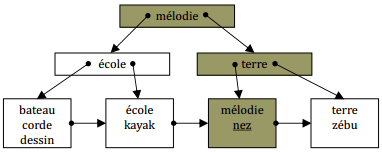
Insertions successives des enregistrements : zébu, dessin
Insertions successives des enregistrements : corde, terre.
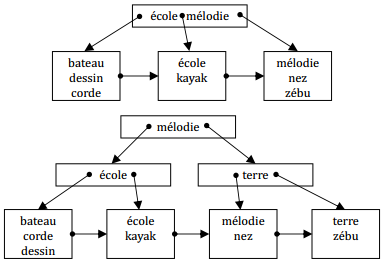
IX-M-9. Suppression d'un enregistrement▲
(Il s'agit de supprimer l'enregistrement dont la clé c est donnée.)
début
Rechercher l'enregistrement de clé c.
si il n'existe pas alors
La suppression est terminée.
sinon
Le nœud courant est celui qui contient l'enregistrement de clé c.
répéter
Soit n le nœud courant, p son adresse, s le contenu de n.
Supprimer l'enregistrement à supprimer de s.
si longueur(s) ≥ (m + 1) / 2 ou si n est la racine alors
Enregistrer s dans p.
La suppression est terminée.
sinon
Fusion du nœud courant
fsi
jusqu'à ce que la suppression soit terminée.
fsi
fin
IX-M-10. Fusion d'un nœud▲
(Il s'agit de fusionner le nouveau contenu s du nœud courant avec le contenu de son frère gauche ou de son frère droit.)
début
si la fusion se fait avec le frère gauche alors
Soit n2 le nœud courant et n1 son frère gauche.
Ré-associer sa clé au premier enregistrement de s,
si n2 est un nœud non terminal.
Soit s' la concaténation du contenu de n1 avec s.
sinon (la fusion se fait avec le frère droit)
Soit n1 le nœud courant et n2 son frère droit.
Ré-associer sa clé au premier pointeur du contenu de n2,
si n2 est un nœud non terminal.
Soit s' la concaténation de s avec le contenu de n2.…
si longueur(s') ≤ m alors
Enregistrer s' dans n1.
Supprimer n2.
si n1 est fils unique alors
Supprimer le père de n1.
La suppression est terminée (la hauteur de l'index a diminué de 1).
fsi
Le père de n2 devient la page courante et l'enregistrement de ce nœud
qui pointe vers n2 devient l‘enregistrement à supprimer.
sinon
Découper s' en deux séquences s'1 et s'2 de longueurs égales à un item prêt.
Enlever sa clé au premier item de s'2, si n2 est un nœud non terminal.
Enregistrer s'1 dans n1 et s'2 dans n2.
Remplacer dans le nœud père de n2, la clé de l'enregistrement qui pointe vers n2,
par la première clé de s'2.
La suppression est terminée.
fsi
fsi
fin
IX-M-11. Suppressions dans l'index dico▲
Suppressions successives des enregistrements : kayak, corde
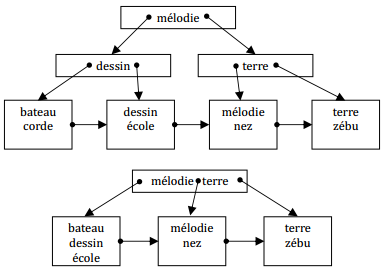
IX-M-12. Performances▲
Le nombre de lectures de nœuds pour accéder à un enregistrement est égal à la longueur d'une branche, c'est-à-dire à la hauteur de l'arbre.
La hauteur maximum (hmax) de l'arbre est obtenue quand la racine est réduite à deux enregistrements et les autres nœuds ne sont remplis qu'à moitié, c'est-à-dire ne contiennent que (m + 1) / 2 enregistrements.
Calculons hmax en posant n = (m + 1) / 2 :
- au 1er niveau, l'arbre possède 2 enregistrements ;
- au 2e niveau, il en possède 2n ;
- …
- au ie niveau, il en possède 2ni-1.
Soit N le nombre d'enregistrements de l'index. On a :
- 2nhmax-1 = N et donc hmax = logn(N / 2) + 1
Par exemple, si l'on suppose :
- que l'on peut ranger 99 enregistrements par nœuds,
- qu'il y a 106 enregistrements dans l'index, alors m = 99, n = 50.
On a : log50(106/2 + 1) ≈ 3,35.
Il faut donc 4 lectures de bloc disque dans le pire cas pour retrouver un enregistrement à partir de sa clé.
IX-N. Hachage▲
Le hachage repose sur la construction d'une fonction dite de hachage qui, appliquée à la clé d'un enregistrement, fournit l'adresse de cet enregistrement.
Le hachage est dit statique ou dynamique selon que la fonction de hachage est fixée ou évolue durant la vie de l'index.
Un index à accès par hachage peut être organisé avec ou sans répertoire.
IX-N-1. Hachage statique▲
Nous présentons en détail l'organisation avec répertoire puis, sur un exemple, l'organisation sans répertoire.
IX-N-1-a. Organisation▲
Un index à accès par hachage statique avec répertoire est un quadruplet (N, h, P, R) où :
- N est un nombre entier positif ;
- h est une fonction de hachage qui, appliquée à une clé, produit un nombre entier compris entre 0 et N - 1, appelé code haché (« hash-code ») ;
-
P est un ensemble de pages stockées sur disque.
Chaque page contient une liste d'enregistrements (c a) où :- c est la clé,
- a est l'information associée ;
- R est un répertoire de N cases. Chaque case i (0 ≤ i ≤ N - 1) est le début d'une chaîne (éventuellement vide) de pages dont tous les enregistrements sont tels que H(c) = i ;
- les pages de cette chaîne à partir de la 2e position sont appelées pages de débordement (« overflow »).
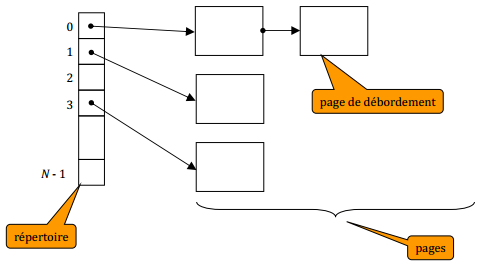
IX-N-1-b. Fonction de hachage▲
La fonction de hachage s'applique à une clé, que nous supposerons être une chaîne de caractères, et à un nombre entier N. Elle retourne un nombre entier compris entre 0 et N - 1.
Il n'est en général pas possible de construire une fonction de hachage injective, c'est-à-dire telle que :
- c1 ≠ c2 ⇒ h(c1) ≠ h(c2).
On construit donc une fonction qui minimise le nombre de collisions et les répartit uniformément.
Les deux techniques les plus utilisées sont la division et le pliage.
Dans les deux cas, on construit à partir des codes des caractères de la clé c, un nombre k grand devant N. La valeur de h(c) est alors calculée comme suit :
- Division. h(c) est le reste de la division de k par N. Il est montré que l'on a intérêt à choisir N premier.
- Pliage. On découpe la représentation binaire de k en tranches de b bits. h(c) est égal au « ou exclusif » des nombres binaires ainsi obtenus.
IX-N-1-c. L'index dico par hachage avec répertoire▲
N = 5 : répertoire de 5 cases,
3 enregistrements au maximum,
h(c) = (somme des codes ASCII des caractères de c) modulo 5.
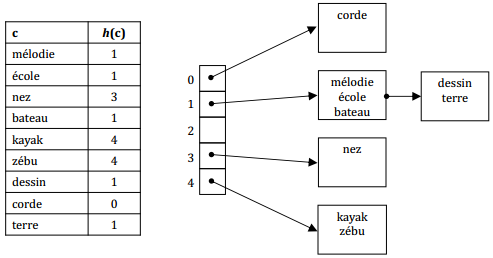
IX-N-1-d. Recherche d'un enregistrement▲
(Il s'agit de rechercher l'enregistrement dont la clé c est donnée.)
début
Parcourir les pages liées à la case h(c)
jusqu'à trouver une page qui contienne un enregistrement de clé c :
c'est l'enregistrement recherché.
si la fin de la chaîne est atteinte alors
L'enregistrement recherché n'existe pas.
fsi
fin
IX-N-1-e. Insertion d'un enregistrement▲
(Il s'agit d'insérer un nouvel enregistrement de clé c et d'information associée a.)
début
Rechercher l'enregistrement de clé c.
si il existe alors
L'insertion est terminée.
sinon
Parcourir les pages liées à la case h(c) jusqu'à en trouver une qui
possède une place suffisante pour le nouvel enregistrement.
si il en existe une alors
Y insérer l'enregistrement : l'insertion est terminée.
sinon (le bout de la chaîne est atteint)
Créer une nouvelle page.
L'ajouter au bout de la chaîne des pages liées à la case h(c).
Y insérer l'enregistrement : l'insertion est terminée.
fsi
fsi
fin
IX-N-1-f. Suppression d'un enregistrement▲
(Il s'agit de supprimer l'enregistrement de clé c.)
début
Rechercher l'enregistrement de clé c.
si il n'existe pas alors
La suppression est terminée.
sinon
Supprimer cet enregistrement de la page qui le contient.
si cette page devient vide alors
La supprimer et remettre à jour
la chaîne des pages.
La suppression est terminée.
fsi
fsi
fin
IX-N-1-g. L'index dico par hachage sans répertoire ▲
On peut éviter l'utilisation d'un répertoire en créant un index de N pages contiguës. Le code haché donne alors directement accès à la page contenant les clés recherchées.
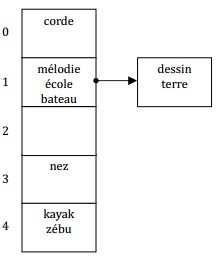
IX-N-1-h. Performances▲
Sans répertoire et avec un bon ajustement des valeurs de N et du nombre d'enregistrements par page, on peut accéder à un enregistrement en 1,1 ou 1,2 accès disque en moyenne.
On peut obtenir la même performance avec un répertoire pourvu que celui-ci tienne en mémoire centrale.
Le répertoire permet de ne pas associer inutilement une page à un code haché non instancié (2 dans notre exemple). Par contre, un répertoire occupe de la place et s'il ne tient pas en mémoire centrale, le nombre d'accès disque sera augmenté.
Le hachage statique est mal adapté à un fichier de données très évolutif, car la taille du répertoire peut s'avérer sous-évaluée, entraînant un accroissement du nombre de pages de débordement et donc du nombre d'accès disque.
Pour le pallier, des méthodes de hachage dites dynamiques ont été proposées, qui font évoluer la fonction de hachage en fonction du nombre d'enregistrements.
IX-N-2. Hachage dynamique▲
L'idée est la suivante : lorsqu'une page est saturée, au lieu de créer une page de débordement, on fait évoluer la fonction de hachage, afin d'assurer que la recherche d'un enregistrement ne nécessitera qu'un seul accès à une page.
Deux méthodes ont été proposées :
- le hachage extensible, par Fagin et al. En 1979 ;
- le hachage linéaire par W. Litwin en 1980.
IX-N-2-a. Hachage extensible▲
Une suite de bits est associée à chaque clé.
L'évolution de la clé de hachage consiste à augmenter le nombre de bits à prendre en compte dans une clé pour trouver la case du répertoire qui pointe vers la page contenant l'enregistrement associé à cette clé :
- si tous les enregistrements tiennent dans une seule page, aucun bit ne sera à prendre en compte ;
- s'ils occupent 2 pages, 1 bit sera à prendre en compte ;
- s'ils occupent 3 ou 4 pages, 2 bits seront à prendre en compte ;
- …
IX-N-2-b. Organisation▲
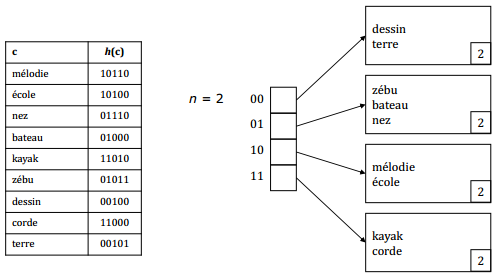
La fonction de hachage h associe à chaque clé une séquence suffisamment longue de bits (32, par exemple).
L'index est composé de deux parties :
- un ensemble de pages ;
- un répertoire de 2n cases (n ≥ 0, profondeur du répertoire) dont chacune contient un pointeur vers une page.
Plusieurs cases consécutives du répertoire peuvent pointer vers la même page.
Un enregistrement de clé c est stocké dans la page pointée par la ie case du répertoire telle que i est égal au nombre formé par les n premiers bits de h(c).
À chaque page est associé un nombre entier m (0 ≤ m ≤ n), appelé profondeur de la page.
Si une page a la profondeur m, alors il y a 2n-m cases du répertoire qui pointent vers elle.
IX-N-2-c. L'index dico par hachage extensible▲
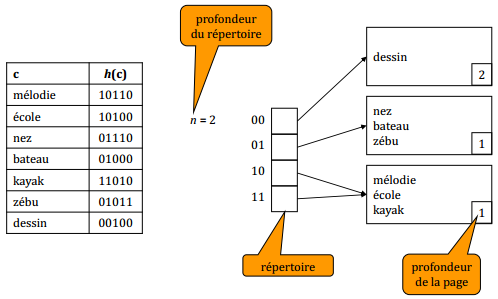
IX-N-2-d. Insertion d'un enregistrement▲
(Il s'agit d'insérer un enregistrement e de clé c)
début
Rechercher la page P qui devrait contenir e : soit m sa profondeur.
si P contient e alors
L'insertion est terminée.
sinon
si P n'est pas saturée alors
Insérer e dans P : l'insertion est terminée.
sinon
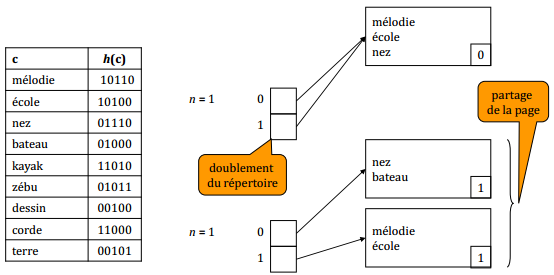
si m < n alors (partage d'une page en 2)
Créer une nouvelle page P'.
m = m + 1
profondeur locale de P = profondeur locale de P' = m.
Enregistrer dans P' tous les enregistrements de P
dont le me bit est égal à 1.
Faire pointer vers P' chaque case du répertoire qui pointait vers P,
si son me bit est égal à 1.
Recommencer l'insertion de e.
sinon (doublement du répertoire)
Doubler la profondeur du répertoire
en dédoublant chaque case du répertoire.
n = n + 1.
Recommencer l'insertion de e.
fsi
fsi
fsi
fin
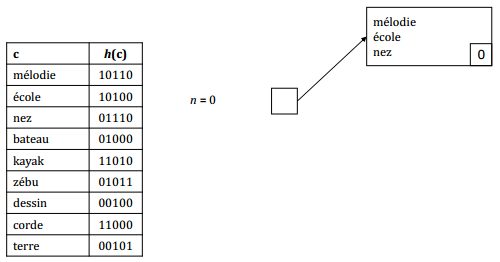
IX-N-2-e. Construction de l'index dico▲
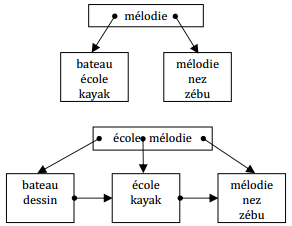
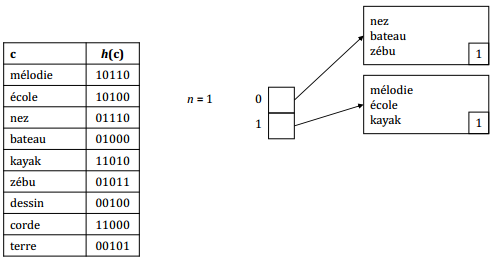
Insertions successives des enregistrements : mélodie, école, nez
Insertion de l'enregistrement : bateau
Insertions successives des enregistrements : kayak, zébu
Insertions successives des enregistrements : dessin
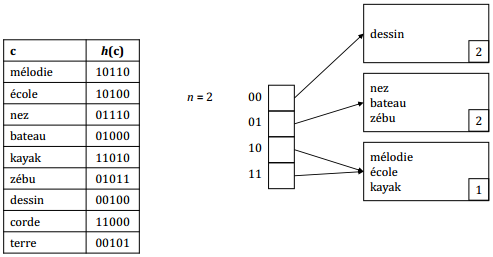
Insertions successives des enregistrements : corde, terre